前言:这本书看的断断续续的,如果不留点笔记可能很快就忘了,所以还是要记录一下。本书作者免费发布 pdf 版本,可以在 Software Engineering at Google (一下可能简称为 SWE)免费下载。因为是个笔记,所以行文可能逻辑比较断裂。
Contents
什么是软件工程
Nothing is built on stone; all is built on sand, but we must build as if the sand were stone. —Jorge Luis Borges

第一部分主要是在讲软件工程的定义,Software Enginner (以下可能简称为 SE)与 Programming 的区别。
最核心的一个想法是,你的代码的生命周期是多久?Google 的新项目往往默认项目会存在十年——这样一来,基础组件升级、依赖变化、团队组成都可能会变化,从而最终影响决策、影响设计。
这一点上国内很多项目肉眼可见的做的不好,最典型的莫过于百度的博客。当然这不意味着个 Google 的产品做得多好,但是这个思维方式确实很有用。当你设计的时候想的是要用十年,很多设计和决策就就和短期项目完全不同了。
我猜可能有很多人会有不同意见,比如像下面这个图里的例子

我觉得也并非不可调和,业务驱动的产品,很多时候就是需要快速试错,上线一个 demo 能用就行——这种情况就是定位为 demo,定位为 programming 就好了。另一方面,这也和从业人员对 SE 了解太少,公司无法做到将 SE 融入到日常有关,如果 SE 就是 Infra 的一部分,快速 demo 与 SE 并不冲突,甚至能相辅相成,自然是最好的——侧面上看,从 Google 出来的人,没有一个不在夸内部 Infra 好的,其他大部分公司则少很多。
时间与变化
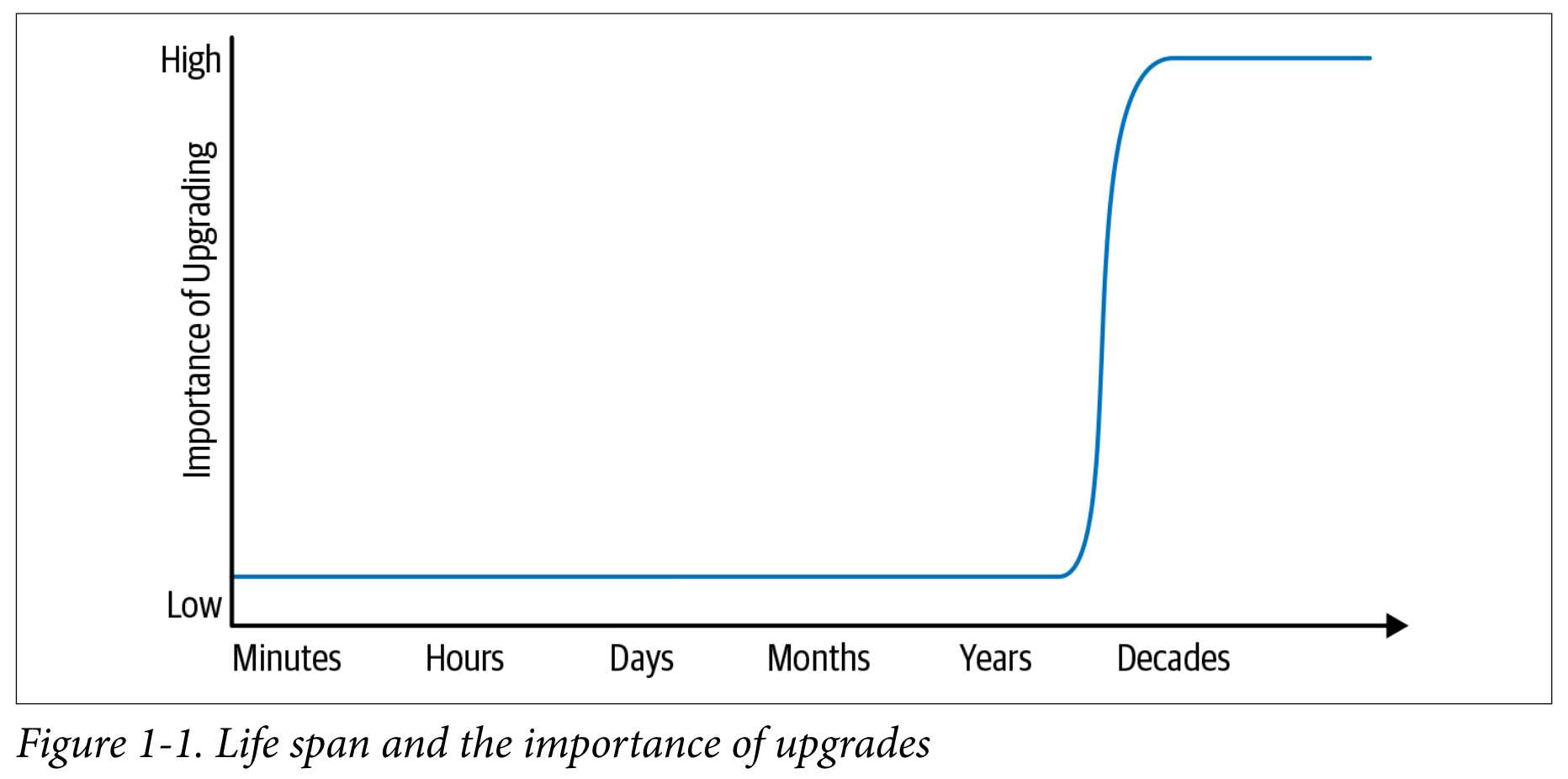
项目的维护成本会随着项目的生命周期增长而飞速增长。
从一个较长的时间尺度看,软件的变化是一定的,因为你的依赖,无论是显式依赖的还是隐式依赖总会变,除了技术原因,因为商业原因也可能会变。
如果项目一开始没有做好“拥抱变化”的准备,那么真的到了需要变化的时候是非常痛苦的,主要是三个原因互相影响:
- 项目之前没有做好这方面的准备,所以可能存在一些隐式的假设
- 工程师没有这方面的经验
- 变化的规模很大,因为这是数年的代码要一次性的改变,而不是逐步的渐进升级
然后因为考虑到上面这些的难度,很多公司/项目大家最后的决定就是:别动它了。或者,可能是低估了难度,升级碰到种种问题,完成一次之后形成一个经验——以后别动它了。
所以 Google 的经验就是,大型项目最最重要的工作就是维持项目的“可变性”,避免项目变成一坨巨大的不能改动不能升级的东西。
这部分让我想到陈皓(左耳朵耗子)的一篇文章:开发团队的效率,里面提到了集中开发模式,其中“‘WatchDog式’软件开发”和“‘故障驱动式’软件开发”和这里说的“代码无法变化”很像。其实就是原有代码动不了,那么只能是在外面整个辅助的“watchdog”(好听一点的话,也可以说是包一层),或者出了问题在针对性的搞一搞,没问题千万别动。
确实在很多情况下也不失为一个可行之策,但是只能用于短时间的搞,因为长此以往软件的复杂度显然会层层上升,最后没有人能够理解整个系统,软件生命也就快走到尽头了。
海拉姆定律(Hyrum’s rule),人们会依赖所有你的 API 的所有可被观测到的特性,即使这些特性不是你文档里承诺的特性,包括 API 的时间、空间的种种隐藏表现。
这个定律之于软件开发就像是熵增定律之于热力学。
Hash Table Ordering
这里有个非常好的例子,就是 Hash Table 的顺序,因为这个例子很好,所以我在原文之外多补充一点。
下面是在我的一个开发环境运行 Python3 的结果:
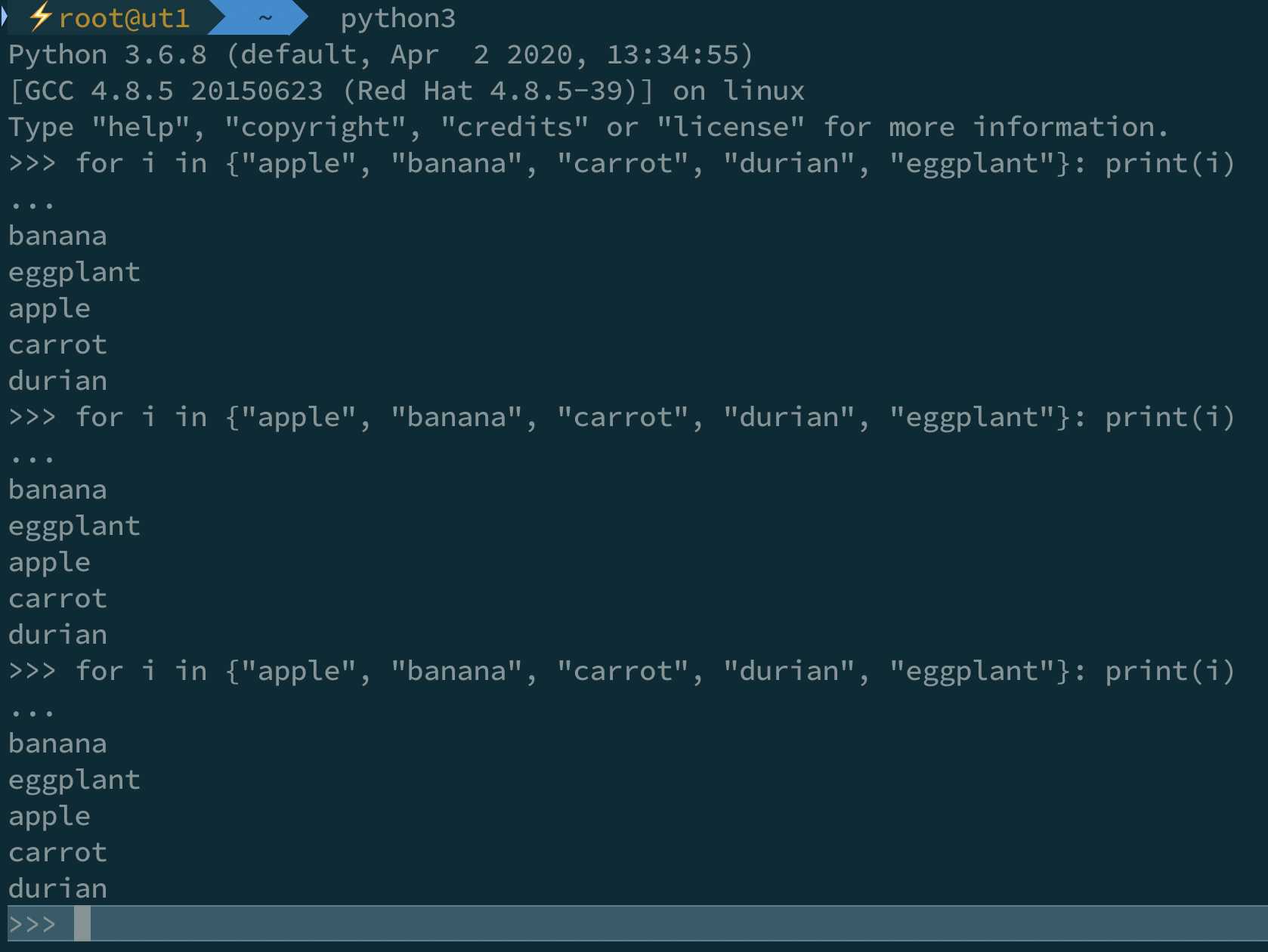
粗看起来,每次运行结果是固定的,虽然不是按照我们输入的顺序输出,但是保持了一个神奇的规律性。
然而,如果你写代码只实验到这一层就下定论,毫无疑问你将会整个大事故,因为:
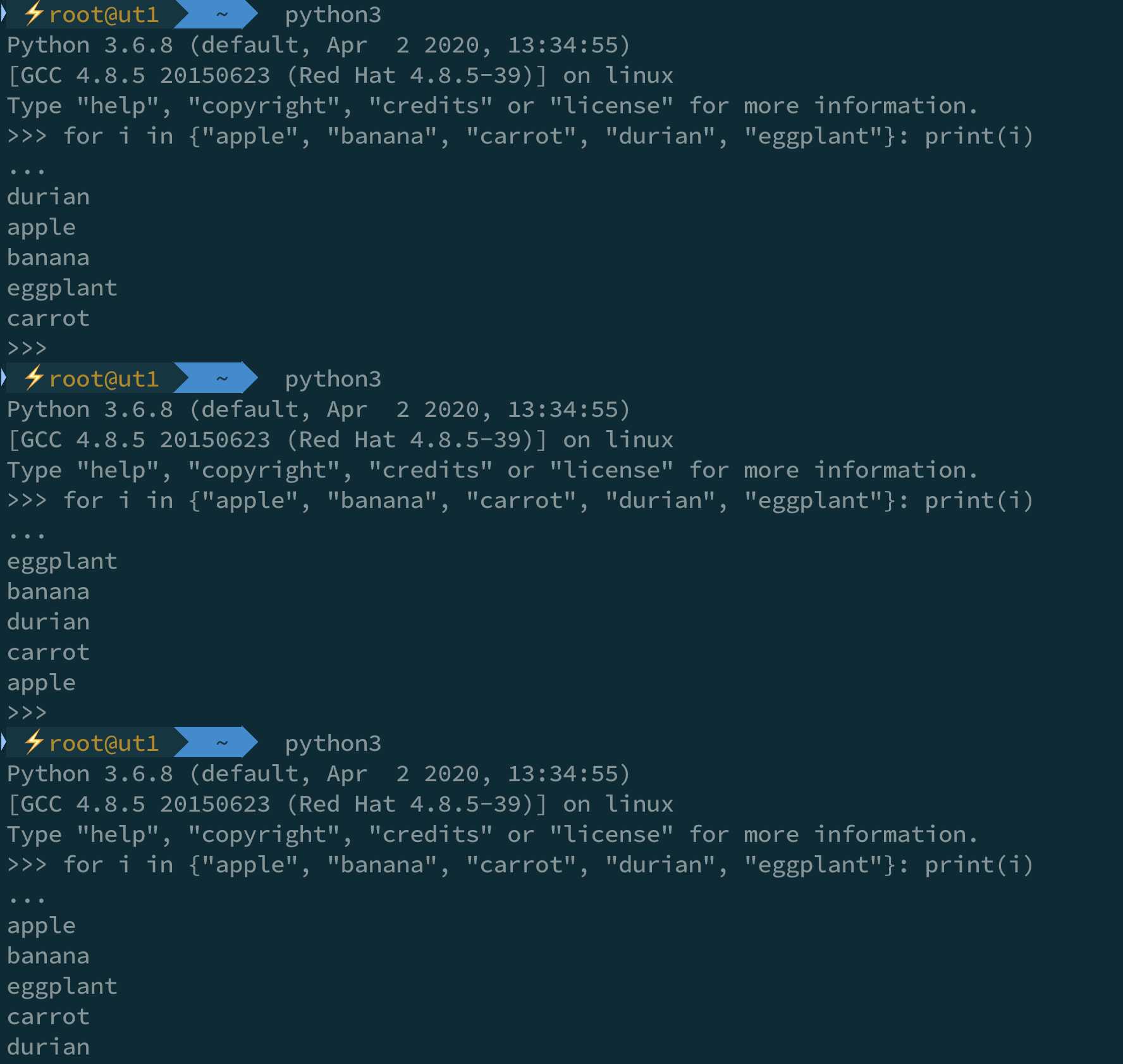
也就是说每次 Python 解释器重新运行时,Hash 的结果都可能会发生改变,为什么要这样?
其实从 Hash 的本质上讲,你需要的只是一个 Hash 函数,比如这样:
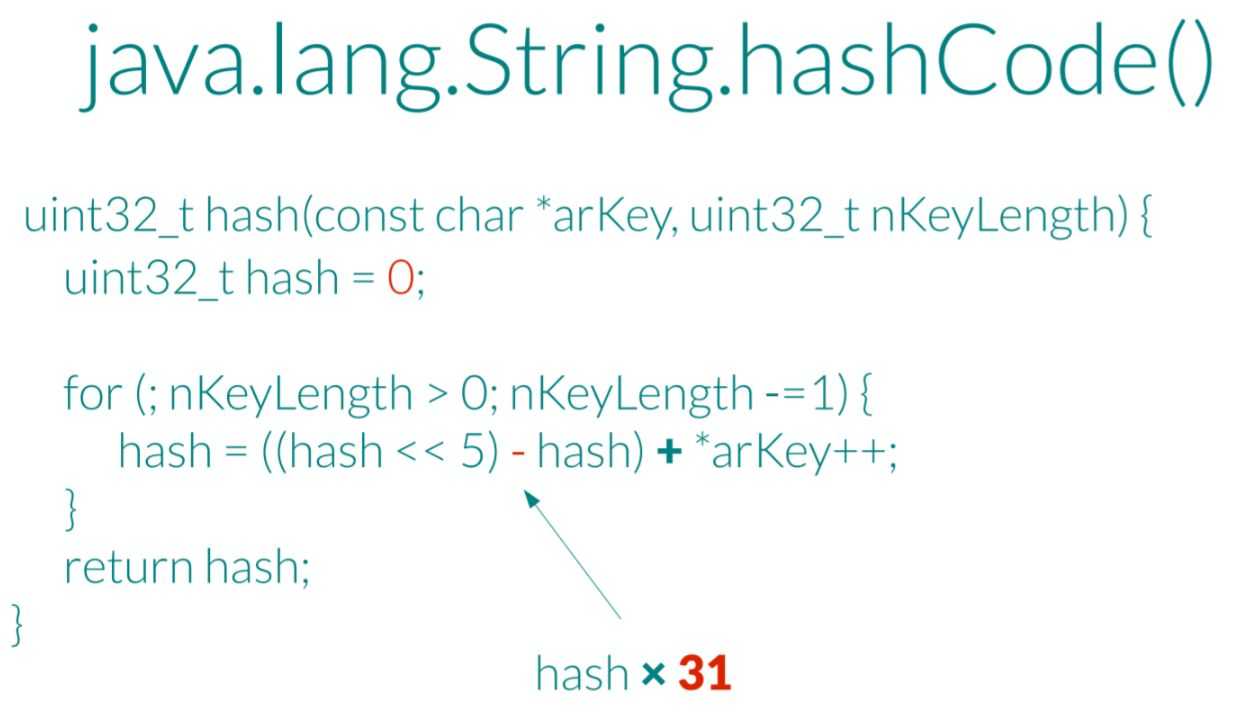
然而根据这个函数,其实你可以轻易构造出很多“哈希碰撞”的情况:

这样一来,只要构造出几万个同样哈希的字符串,把它们提交给服务器做哈希表, 就能用很低的成本将服务器打瘫了。
这个成本具体有多低呢?依2011年的实验数据,攻击一台基于Java(Tomcat)的服务器时,仅仅需要6KB/s的流量就能打瘫一颗 Intel i7 处理器,1GB/s的流量可以打瘫 100000 颗 Intel i7 处理器,性价比远超TCP半开连接等传统的拒绝服务攻击。
最容易的解决方案,其实和前段时间的“log4shell”很像——不要信任用户输入,或者限制单个 Hash Table 的大小、限制输入的规模等等,但是这个方法肯定不 Scale——设计这个限制的开发者一旦离职,下一个接手的人一定会认为这是什么神经病整这个?!转手就删了~
根据生日悖论我们可以知道你不可能设计一个精妙的算法能够避免哈希碰撞,只要攻击者掌握了算法的细节,就一定能够设计出一个碰撞的攻击。
因此现在的低于方法都是在算法中加入一个随机种子,放每次哈希结果产生一定随机性,这样攻击者知道算法细节,但不知道这个随机种子,也就无法构造碰撞了。
反过来攻击者的攻击目标也就在刺探这个种子上了,这里不再详述,可以看这篇文章:什么是哈希洪水攻击(Hash-Flooding Attack)?
回到 SWE,你可以看到 Hash Table 的 Ordering,从一开始有序,到现在无序,那么就一定是稳定的么?不同的语言、不同的编译器、不同的数据结构还会不会有变化?放在一个很长的时间尺度上,这些都无法保证。
那么,既然软件变化这么难,有没有可能把一开始的目标定成,我们的软件,设计好就不改变了?我花海量的时间做提前的用户调研、业务调研,然后软件使用底层尽量不变的技术(比如纯 C 的库变化往往要少,或者只依赖 POSIX 这种很稳定的东西)一次成功,再也不改了?
想想 SSL heartbleed、想想 Meltdown and Spectre,就算需求没有变化,底层也可能会有安全问题导致的升级和变化,所以赌我的软件永远不变是风险极大的(基本上可以说是不可能的)
此外,因为新硬件、新算法或者是底层技术的发展,底层库或者基础设施可能效率会越来越好,如果你的软件持续不更新、不随之变化,那么可能在效率上就会被淘汰。
综上,变化不是天生的好事,不需要为了改变而改变,但是拥有这种能力显然会让我们处于巨大的竞争优势。
可扩展性与效率
Codebase 的 sustainable 的定义:整个代码在整个生命周期内都可以随时安全的改变。
如果变化的代价很大,那么人们就会倾向于不去动他。
温水煮青蛙原则:问题总是慢慢变糟,而不是忽然一下坏掉了。
经验是:人们很容易设计出不可扩展的策略(政策),识别不可扩展的策略的方式——假设整个组织规模增长 10 倍、100 倍,那么这个策略还能否有效?
依赖问题
对于小项目来说,依赖升级可能就是口头的一句——“新版本发布了,请使用新版本”
很快随着规模变大,大家就发现这样不行,此时策略一般会改为——“底层的改动不能影响上层”,在 Google 这个策略叫做 Churn Rule。因为这样可以把升级的兼容性统一交给底层团队解决,底层团队会更有经验处理这些问题,而不是让上层调用者去学习研究升级里面的问题。简单来说就是达到一个效果 Expertise scales better.
分支问题
这个问题倒是很常见,Google 的策略也很出名,就是 mono repo。因为开发分支时间一长就有主分支升级的问题,合并冲突的问题,合并时主线行为变化的问题等等一系列头痛问题。这个会在后面详细讲。
The Beyoncé Rule
所有行为应该通过 CI 系统验证,不是通过统一的 CI 系统验证的话,测试再复杂、精巧,都是不被认可的,都被认为是一次性的。
知识是病毒,专家是载体,只要有好的交流方式,知识就会不端传播,就会有新的专家成长。
Google 在 2006 年计划升级编译器,在此之前他们 5 年没有升级编译器,大部分代码都在一个编译器上验证。可想而知这次升级非常困难,因此经过这次升级之后,Google 做了一个与大部分公司相反的决定——Google 将升级编译器整合到自动化系统,并且将相应的验证限定到小的变化,从此这个事情反而成了 Google 的一项优势。
所以,你越是频繁的改变你的 Infra,他就会越容易。经过不断的升级,代码将不再依赖底层的实现细节,而是更只依赖语言、操作系统的实际抽象。
左移
简单来说,事情做的越早,成本越低。
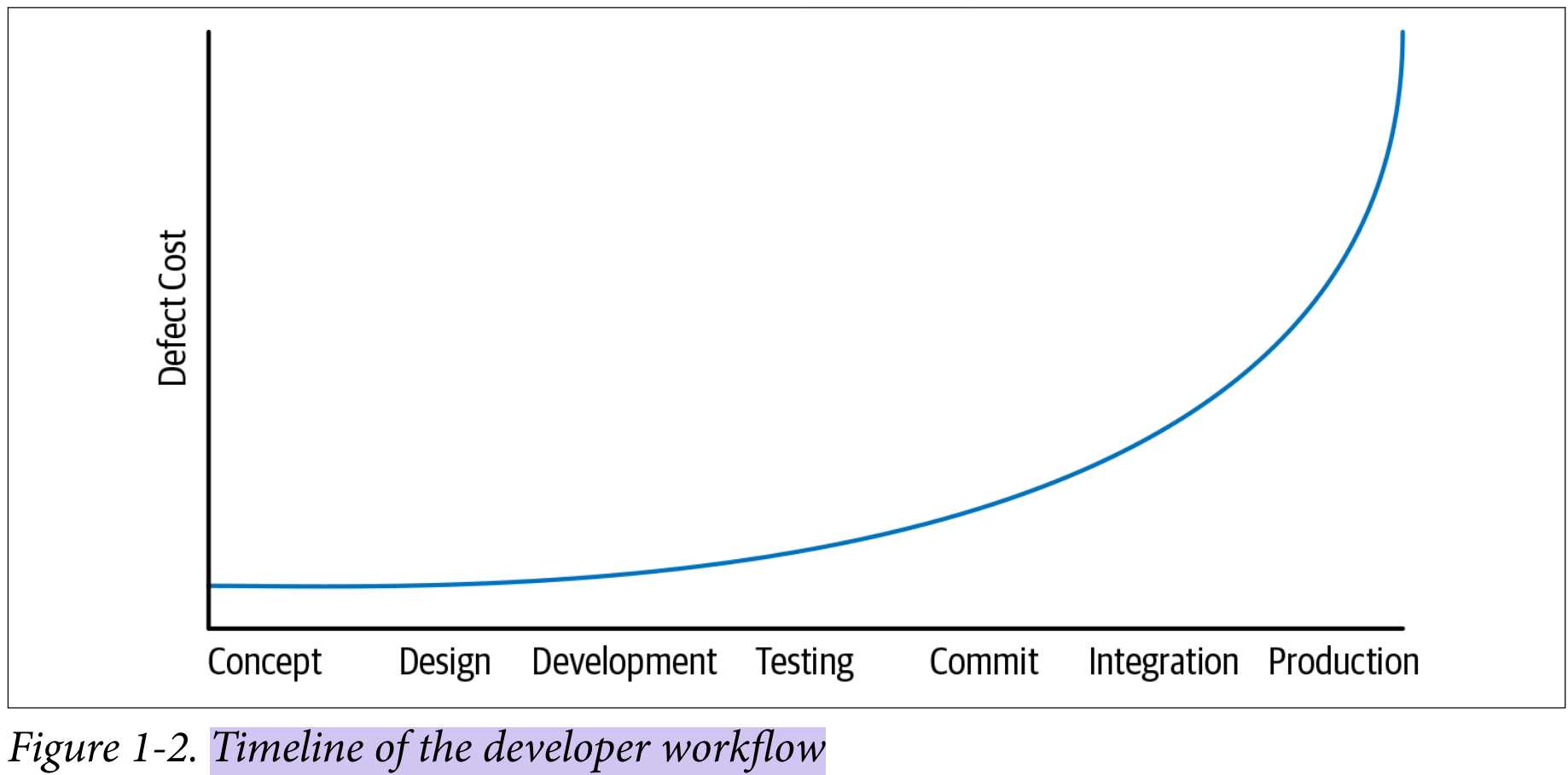
权衡和收益
重要的是形成共识,而不是完全一致。换句话说,在 Google,很可能会有人说“我不赞同你的数据/评估,但我知道你如何形成这个结论”。
因此 Google 推崇大家通过数据得出结论,而不是“我认为”、“我以为”、“因为别人”。
成本应当包含以下这些方面:
- Financial costs (e.g., money)
- Resource costs (e.g., CPU time)
- Personnel costs (e.g., engineering effort)
- Transaction costs (e.g., what does it cost to take action?)
- Opportunity costs (e.g., what does it cost to not take action?)
- Societal costs (e.g., what impact will this choice have on society at large?)
Google 构建了良好的分布式 build 系统,节省了程序员的时间,但是发现带来了从此无人关心程序的编译时间的问题。但总的来说,还是收益大于成本,
Revisiting Decisions, Making Mistakes
从长远来看,一切决策都可能会从一开始正确变为不正确,甚至一开始都不正确。因此需要机制来 revisit 当初的决策。如果决策是基于数据驱动的,那么因为数据改变,很容易得出之前的决策不合适的结论,如果是拍脑袋决策,就没那么容易了。
当然,总有些东西是很难量化的,这就只能靠判断力了。
本章总结
Programming 意味着快速产出 code,而 SE 则是一系列策略、实践和工具。这些不仅能够让软件与时间相抗争,还能保证团队协作的质量。
最后,如果不想一字一句的读本章的 24 页内容,那么看下面的总结就够了:
- “Software engineering” differs from “programming” in dimensionality: programming is about producing code. Software engineering extends that to include the maintenance of that code for its useful life span. —— SE 的关键在于扩展代码的生命周期
- There is a factor of at least 100,000 times between the life spans of short-lived code and long-lived code. It is silly to assume that the same best practices apply universally on both ends of that spectrum. —— 软件生命周期可能有 100,000 倍的差别,因此造成了策略的不同
- Software is sustainable when, for the expected life span of the code, we are capable of responding to changes in dependencies, technology, or product requirements. We may choose to not change things, but we need to be capable. ——只有当软件可以在生命周期内随时更改才可称之为是 sustainable
- Hyrum’s Law: with a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody. —— Hyrum 定律
- Every task your organization has to do repeatedly should be scalable (linear or better) in terms of human input. Policies are a wonderful tool for making process scalable. ——组织内每个重复的事情都需要是可扩展的
- Process inefficiencies and other software-development tasks tend to scale up slowly. Be careful about boiled-frog problems. ——小心温水煮青蛙问题
- Expertise pays off particularly well when combined with economies of scale.
- “Because I said so” is a terrible reason to do things. ——当专业知识和规模经济相结合,回报将会异常丰厚
- Being data driven is a good start, but in reality, most decisions are based on a mix of data, assumption, precedent, and argument. It’s best when objective data makes up the majority of those inputs, but it can rarely be all of them. ——数据驱动是个好的开始,但大部分决策都是数据、假设、经验、争论的结合
- Being data driven over time implies the need to change directions when the data changes (or when assumptions are dispelled). Mistakes or revised plans are inevitable. ——数据驱动意味着数据变化时策略的对应变化,注意复盘决策
这一章内容确实没有太多过人之处,但是能否把“正确的废话”或者“看起来并不特别的策略”贯彻好,可能就是不同公司天花板不同的一大原因吧。