这篇文章是 MIT 6.824 课程安排的一篇阅读材料。
我 Fork 了别人整理的 MIT 6.824 的课程材料,关于这篇文章的内容可以在这里找到:https://github.com/MatheMatrix/MIT-6.824-Distributed-Systems/tree/master/Lectures/LEC04
下面是笔记。
摘要
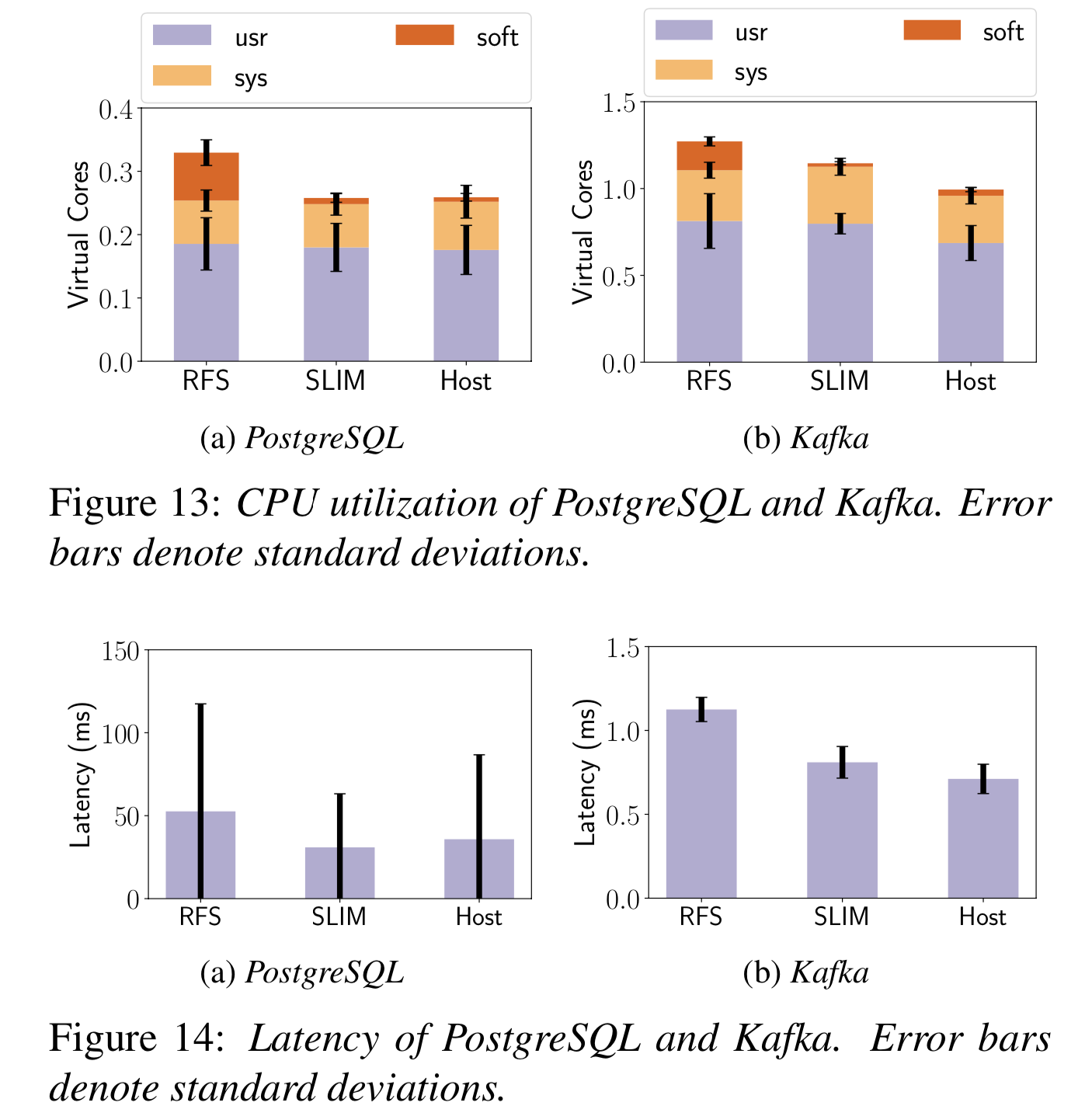
VMware 在 2010 年发布了这篇文章,主要描述它们在 vShpere 4.0 上实现的虚拟机高可用方案,这是一个商用的、企业级的方案,虚拟机性能下降在 10% 以内,虚拟机同步需要 20M 左右带宽。文章提到让这样一个系统支撑企业应用除了复制虚拟机的指令外,还有很多其他问题。
介绍
实现高可用的基本思路是主备,主备最简单的想法就是复制主的所有状态,包括 CPU、内存、IO。但是这个方案无疑需要非常大的带宽。
另一种方法是复制状态机思路,简单的说,这个思路就是把虚拟机当作一个确定状态机,两边先保持一个一致的初始状态,然后保证它们能够一样的顺序接收一样的指令。因为总有一些操作造成的结果不是确定性的,因此还需要额外的工作来保持同步(主要是内存)。
这个思路在物理机上无疑很难实现,但是在虚拟机上就好做很多,因为虚拟机就是一个定义的很完善的状态机,其所有操作、设备都是虚拟化的。但是相比物理机,虚拟机自己也有一些非确定性操作,例如读取时间和发送中断,这就是为什么我们刚才说需要额外操作来保持同步。
VMware vSphere FT 基于确定性重放(deterministic replay),但是增加了必要的额外协议和功能来保证系统功能完整。到写这篇文章时,FT 生产版本还只能支持单 CPU 虚拟机,因为对多 CPU 来说,几乎每次读写共享内存都是非确定性操作,由此带来巨大的性能损失。
这个系统的设计目标只处理 fail-stop 错误,也就是系统一旦出错则立即 stop,而且正确的服务器立刻知道它 stop 了。(分布式系统中的各种错误可以参考:http://alvaro-videla.com/2013/12/failure-modes-in-distributed-systems.html, fail-stop 几乎是最简单的错误类型)
FT 设计
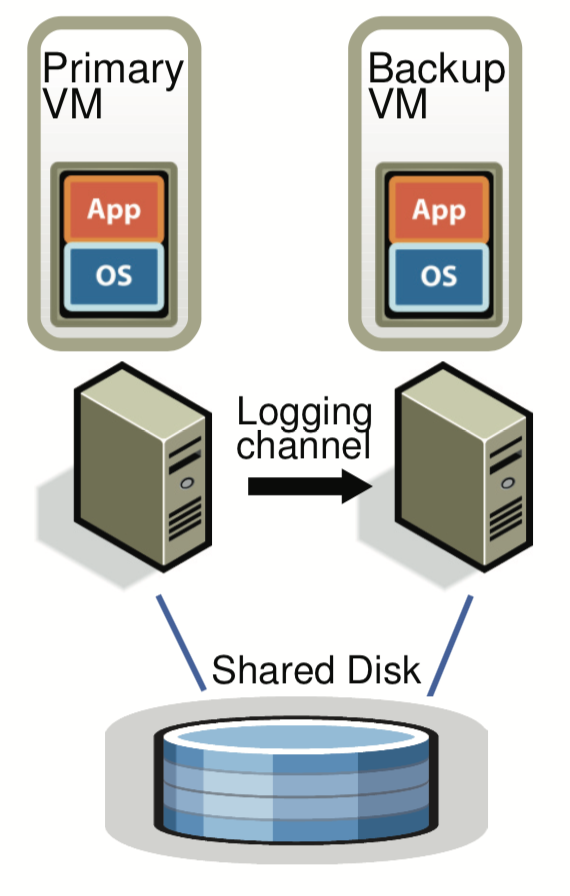
首先我们将备份虚拟机运行在一个和主虚拟机不同的物理机上,备份虚拟机与主虚拟机保持同步和一致但有一个很小的时间差,这时我们称这两个虚拟机处于 virtual lockstep。
两个虚拟机的虚拟磁盘位于共享存储上(例如 FC 或 iSCSI,后面会讨论非共享存储的场景),只有主虚拟机会在网络上对外通告,所以所有网络输入只会进入主 VM,其他输入例如键盘和鼠标也是一样只到主虚拟机。
所有主虚拟机收到的输入,会通过网络(logging channel)来发到备份虚拟机。VMware 通过特定协议做收到确认,来保证主虚拟机失效时不会有数据丢失。
为了检测主虚拟机或备份虚拟机失效,VMware 会在两个服务器上跑心跳,同事监控 logging channel 的流量。
确定性重放(Deterministic Replay)的实现
虚拟机有大量的输入,包括:
还有大量非确定性事件(比如虚拟中断)和非确定性操作(比如读取 CPU 时钟计数器)都会影响虚拟机状态。
难点有三处:
- 正确捕捉所有的输入和不确定性
- 正确的在备份虚拟机上应用这些输入和不确定性
- 确保不太多影响性能
此外,x86 处理器有很多复杂操作会造成未定义的、造成不确定性的副作用。
VMware 确定性重放(deterministic replay)(2007 年的这篇文章更详细的做了介绍:http://www-mount.ece.umn.edu/~jjyi/MoBS/2007/program/01C-Xu.pdf)解决了上述的前两个问题。
确定性重放可以记录虚拟机的所有输入和所有可能的非确定性,并以流的方式记录到一个日志文件里。通过读取这个文件,就可以对虚拟机操作进行重放,同时这个文件还记录了足够的信息来还原非确定操作造成的状态改变和输出。例如定时器、IO 完成中断这些非确定性事件会记录发生在具体哪个指令之后来保证重放时可以让事件发生在相同的位置。
FT 协议
上面说到确定性重发是记录日志的,但很好理解在 FT 实现里,我们不可能这么做,取而代之的是通过 logging channel 来把这些 log entry 发送到备份虚拟机。
备份虚拟机要实时的重放,这里最重要的要求是:
Output Requirement:如果备份虚拟机取代了主虚拟机,那么备份虚拟机要按照之前主虚拟机的输出保持完全一致的继续输出到外界。
这里很重要的一点是备份虚拟机需要保持一致的对外输出,而不是一致的运行——一致的运行是不可能的,因为当主节点宕机时,肯定会有一些不确定性事件(比如中断)造成备份虚拟机与主虚拟机运行的不一致,而这些不确定性可能还没来得及同步,所以怎么保证主虚拟机宕机时,备份虚拟机总能够接得住主虚拟机的输出,让外界以为没有发生中断/切换呢?
比较简单的思路就是延迟对外输出(例如网络报文),就像这样:
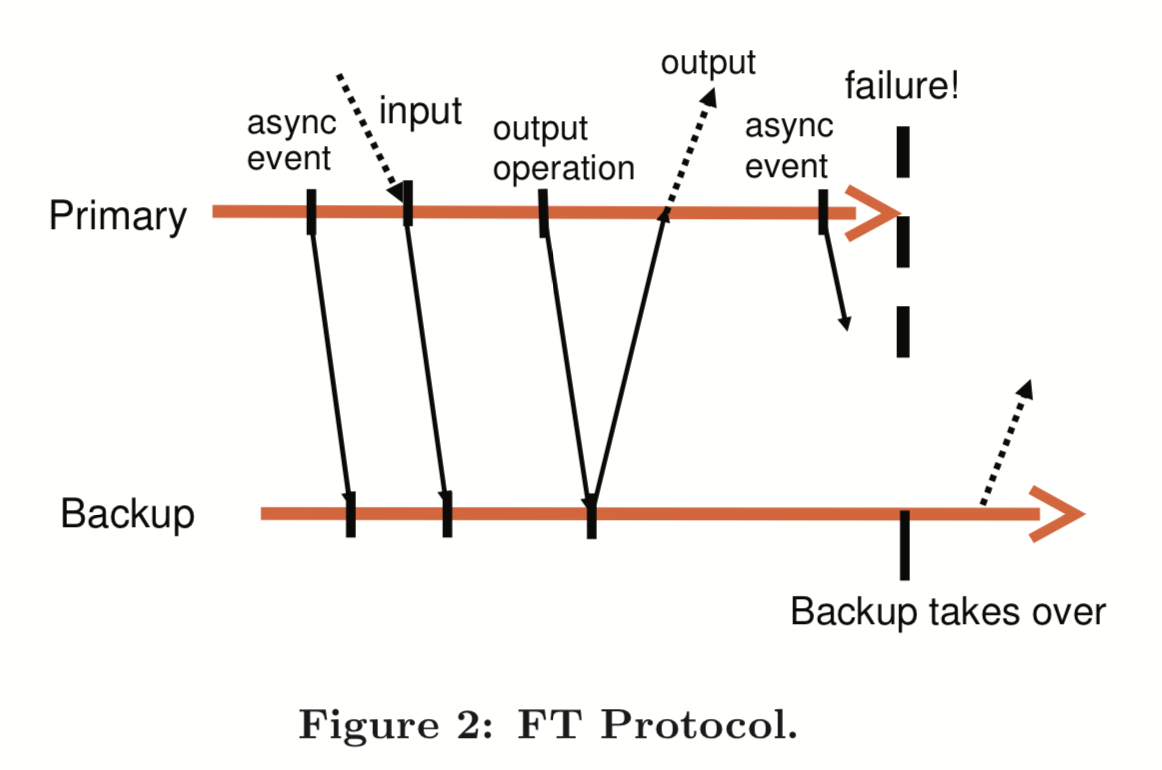
在主虚拟机对外输出前,必须先要把所有的日志发送到备份虚拟机,备份虚拟机确定可以重放出主虚拟机输出时的状态时,主虚拟机才可以对外输出。这样如果主虚拟机宕机,备份虚拟机可以正确达到对外的一致状态。反之,如果备份虚拟机没有收到足够的日志,那么备份虚拟机会分叉。
延迟输出并没有暂停虚拟机,只需要在发送输出前延迟即可,虚拟机可以继续运行,这里和之前的容错系统是不同的(https://courses.mpi-sws.org/ds-ws18/papers/bressoud-hypervisor.pdf, http://www.cs.utexas.edu/users/lorenzo/corsi/cs380d/papers/ftjvm.pdf)
除非主虚拟机输出时引入两阶段提交,否则无法保证 fail-over 时无法保证输出只发生了一次,不过比较幸好的网络或磁盘 IO 上这个不是大问题。
宕机检测与主备切换
当备份虚拟机宕机时,主虚拟机必须立刻退出记录模式,不发送日志(不然会停止输出);主虚拟机宕机时,备份虚拟机则要立刻恢复正常模式,消费完 logging channel 的所有日志然后开始进行执行。此外 VMware FT 还会自动广播 MAC 等来帮助外界知道虚拟机的位置,还需要做一些磁盘 IO(后面描述,主要是磁盘并行和 DMA 的问题)
VMware FT 使用 UDP 来做心跳检测,并且不断监控 logging channel 的流量情况、备份虚拟机的 ack 情况——因为定时器中断的缘故,操作系统应该是总会有日志的。
不过这些检测手段都解决不了脑裂问题,因此 VMware 要求虚拟机一定运行在共享存储上,通过 test-and-set 来防止脑裂。
具体实现
上面只是大概设计,真正将系统可用、鲁棒、自动化还需要很多细节性的工作。
启动和重启备份虚拟机
这里讲 VMware 如何启动一个初始状态一致的虚拟机,对于 VMware 来说可以利用之前的 VMotion。
另一个问题是如何选择物理机来启动备份虚拟机。
管理 Logging Channel
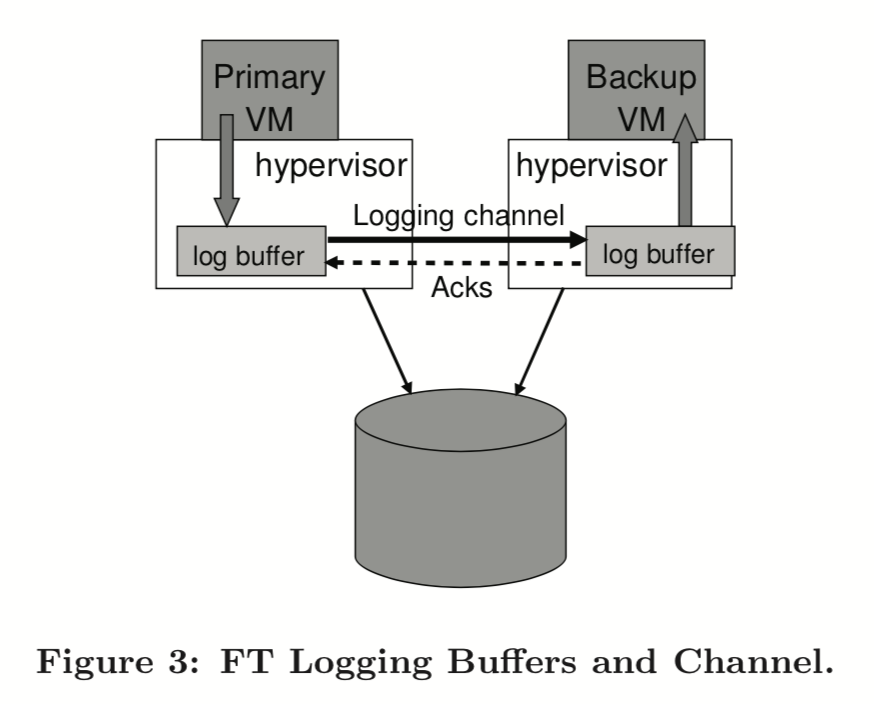
如上图,两边各有一个 log buffer,当备份虚拟机 log buffer 为空时,需要暂停备份虚拟机,反之主虚拟机 log buffer 满时需要暂停主虚拟机。
因此,要非常小心的设计来规避主虚拟机 log buffer 满的情况。为此 VMware 设计了一个机制——当备份虚拟机执行跟不上主虚拟机的速度时,会降低主虚拟机的 CPU 性能,当能跟上时,再慢慢提高主虚拟机的性能,有点像滑动窗口一样。
FT 虚拟机上的控制操作
在 FT 虚拟机上的控制操作也需要考虑,例如所有的资源管理变化(比如调整虚拟机 CPU)都需要同步操作两个虚拟机,因此在 logging channel 里需要加特殊的一些控制 entry。
简单地说,除了虚拟机的 VMotion 之外,所以操作都需要同步。
不过这不意味着 VMotion 不需要修改:
- VMotion 时也要注意不能迁移到同一物理机;
- VMotion 时,备份虚拟机到主虚拟机会有中断重连发生,需要专门处理,特别是迁移备份虚拟机,因为需要主虚拟机控制对外住 IO。
磁盘 IO 实现上的问题
IO 在实现上有不少问题:
- 磁盘操作可能是异步、同步的,这样不同的 IO 可能请求了磁盘的同一位置,造成不确定性;
- 因为磁盘操作可能是通过内存 DMA 的,因此内存的相同位置的读写也会带来 IO 的不确定性;
- 主虚拟机 IO 发出但未完成时宕机,备份虚拟机升级为主虚拟机后无法知道 IO 究竟是否成功。
解决方案是:
- 检测竞争 IO,强行按照主虚拟机的情况顺序化
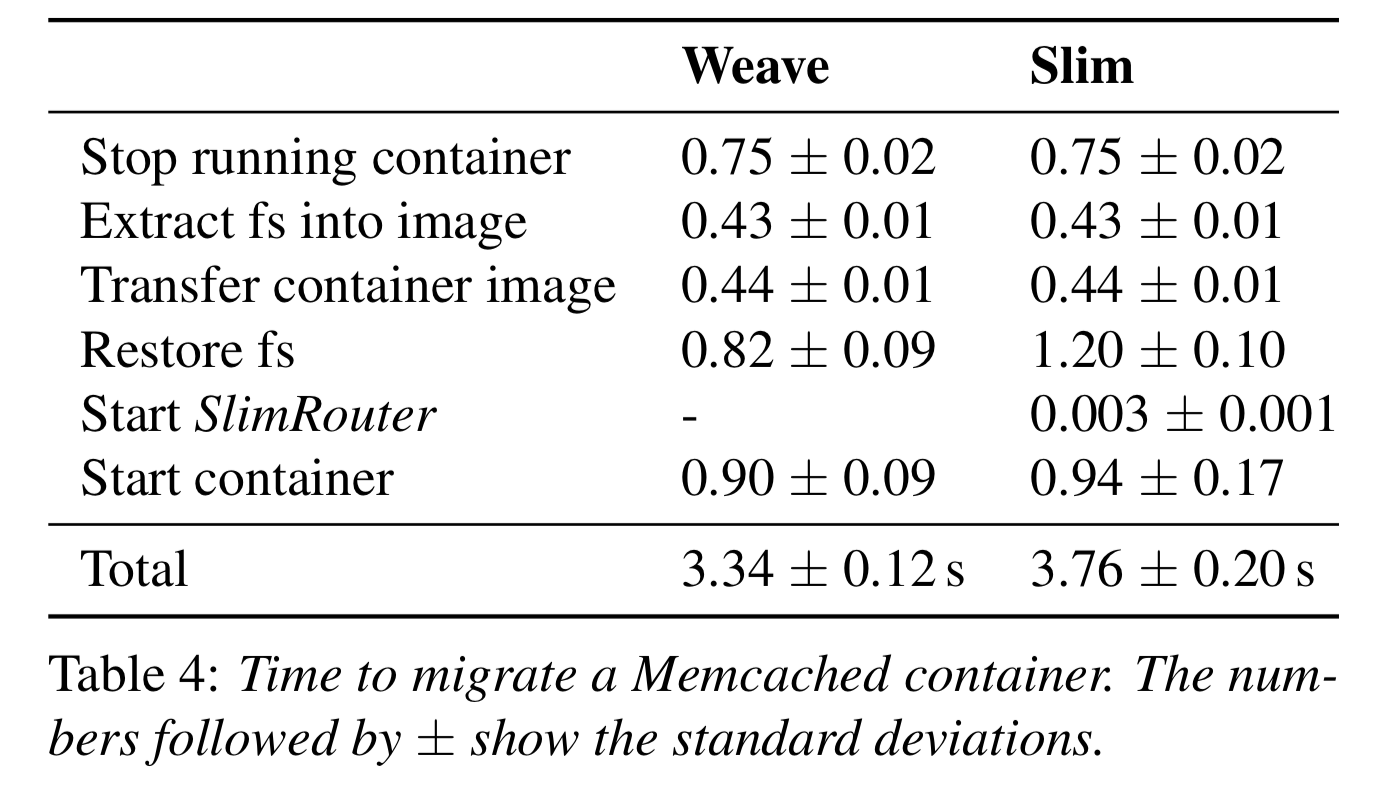
- 对目标磁盘 IO 相关内存做检测和页保护,页保护可以让虚拟机在访问还没完成的 IO 的内存 trap,然后 IO 完成后再恢复虚拟机。但是修改 MMU 的页保护时个非常昂贵的操作,因此 VMware 引入了 bounce buffer。bounce buffer 是一快和大小和所需要磁盘操作的内存大小相同的临时缓存,可以 buffer 住相同位置的 IO 操作。A disk read operation is modified to read the specified data to the bounce buffer, and the data is copied to guest memory only as the IO completion is delivered. Similarly, for a disk write operation, the data to be sent is first copied to the bounce buffer, and the disk write is modified to write data from the bounce buffer;
- 返回 IO 失败可能导致 Guest OS 无法正确处理,所以只好在备份虚拟机升级为主虚拟机的过程中重发 IO。
网络 IO 实现上的问题
为了优化性能,网络很多代码都是异步的,这在 FT 中会带来不确定性,所以很多优化诸如异步更新 Ring Buffer、异步收取 transmit queues 这些要禁用掉。
但直接禁用掉性能又肯定不行,为此需要优化中断机制,通过减少中断。
还有之前我们说过主虚拟机 Output 前需要受到备份虚拟机的 Ack,这个也很损耗性能,解决方案是减少这个延时,其中核心解决方案是减少了备份虚拟机收到 log 到回复 ack 的延时。
设计上的一些其他思路
共享磁盘 vs 非共享磁盘
如果是非共享磁盘,那么备份虚拟机将写入到不同的虚拟磁盘里,类似下图这样:
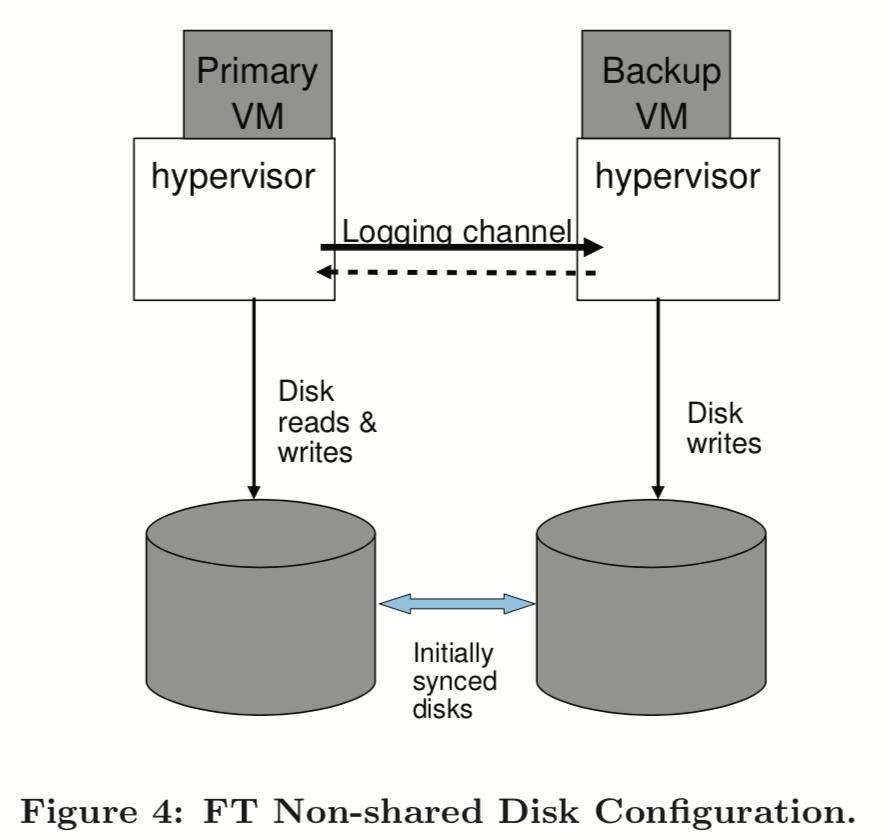
这样 Output Rule 这个设计也需要改变。优点是避免了共享存储的成本、可用性问题,可以想象一下远距离 FT 之类的场景,但是缺点是两个虚拟磁盘必须在刚开始时完全一致(包括内容和行为),而且需要考虑不同步时如何 resync。另外就是脑裂的问题,需要考虑用第三方作为 tiebreaker。
在备份虚拟机上直接读取磁盘
在我们的默认设计里,无论共享磁盘/非共享磁盘,虚备份虚拟机都不会读取自己的虚拟磁盘,因为磁盘读被考虑为一个输入,所以通过 logging channel 来同步。
可以考虑让备份虚拟机执行磁盘读请求,这样就可以减少 logging chennel 的负载,但这样可能降低备份虚拟机的性能,而且要考虑主虚拟机读取成功、备份虚拟机读取失败的场景,最后这里还有主虚拟机、备份虚拟机潜在的竞争问题,总之问题不少。VMware 在测试性能时测试了这个方案,对真实应用来说,会有轻微的性能下降,但会有显著地 logging chennel 带宽的减少。
性能评估
在两个服务器上每个运行了 8核8GB 的内存的虚拟机,服务器用万兆网络直接连起来,不过实际用了远小于 1Gb 的带宽。存储是 EMC Clariion 4 Gb FC 存储。
基本评估
虚拟机空闲时,大概会用 0.5~1.5 Mb 带宽,当有大量网络 IO 时,logging channel 的带宽会显著增大:
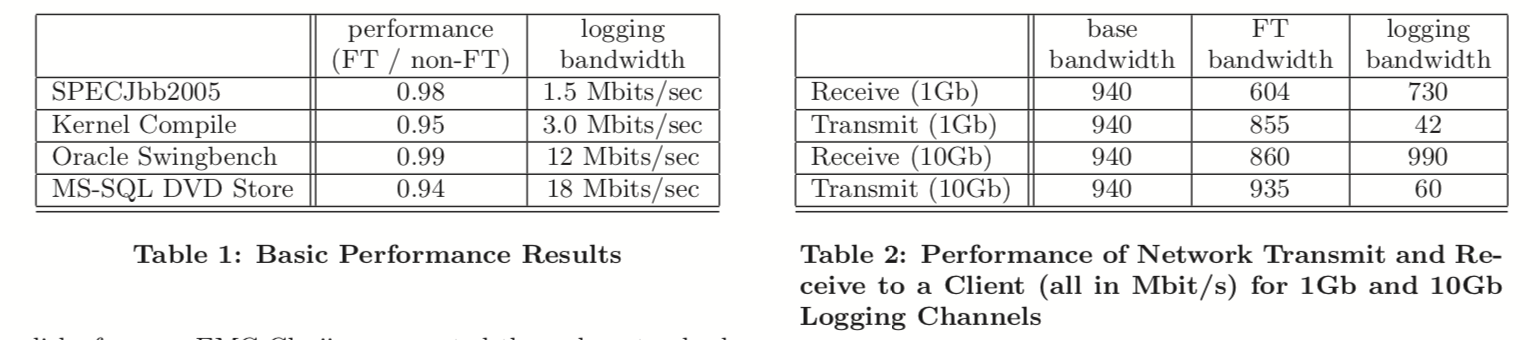
网络性能
网络的挑战很大:
- 高速网络会带来海量中断
- 海量报文都通过 logging channel 同步
- 海量报文的 Output Rule 造成大量延迟
具体参考上面的图
相关工作
我这里就略去了,大家可以直接看原文,此外后面 QEMU 发展了 COLO,又诞生了很多文章,可以在网上搜到,还有 VMware 这里依赖了它之前的确定性重放和 VMotion 的技术,感兴趣的话也需要再去查阅文献。
总结
有几点:
- 因为 FT 所需要的带宽往往并不那么大,因此长距离 FT 也是可能的,可以通过压缩等方法进一步减少 logging chennel 的带宽,但可能增大 CPU 负载;
- 确定性重放的设计只能在单 CPU 虚拟机上保持高效,多处理器是另一个可能的探索方向
- 目前针对的 fail 场景是 fail-stop,另一个可能的探索方向就是扩展到部分硬件失效,比如网络失效或者供电冗余失效等等