Ursa 是美团云 16 就发布过的面向 IaaS 云主机的块存储系统,目前 Ursa 主要有几篇公开文章讨论其架构:
最早:https://tech.meituan.com/2016/03/11/block-store.html 介绍了 motivation、和其他块存储的比较
17 年在知乎专栏发表了基于混合存储的效率优化,和这次 Eurosys 19′ 内容相关:https://zhuanlan.zhihu.com/p/27695512
17 年还有一篇 USENIX 17′ 的文章:https://tech.meituan.com/2017/05/19/speculative-partial-writes-erasure-coded-systems.html 介绍了对 EC 的优化
下面介绍这篇文章,原文地址:https://www.cs.jhu.edu/~huang/paper/ursa-eurosys19.pdf or https://dl.acm.org/citation.cfm?id=3303967
简介
通过追踪块存储的 IO pattern 可以发现其 IO 的 locality 很差,因此相对于使用 SSD 作为 cache layer,Ursa 选择了底层直接使用 SSD-HDD 混布方案,将主副本放在 SSD 上,备副本放在 HDD 上,通过 Journal 来弥补 SSD 和 HDD 之间的性能差距。实验显示之中模式在大部分情况下可以达到与全 SSD 相同的性能,与全 SSD 的 Ceph 和 Sheepdog 相比效果也很好,而且有更高的 CPU 效率。
最近几年有一些提升虚拟磁盘吞吐的研究,例如 NSDI 14′ 发表的 https://www.usenix.org/system/files/conference/nsdi14/nsdi14-paper-mickens-james.pdf ,但低成本的提高虚拟磁盘效率还是很难。通过生产环境的实验以及过去的研究(https://www.usenix.org/legacy/event/fast08/tech/full_papers/narayanan/narayanan.pdf )可以发现块存储 IO 有两个典型特征:
- 大部分情况都是小 IO 为主,偶尔有顺序大 IO
- 读和写的 locality 都很差
因为小 IO 为主,因此 SSD 在构建块存储上一定优于 HDD。但是 SSD 的价格和能耗使得全 SSD 成本太高。因此考虑到第二个特征——locality 弱,使用 SSD 作为 cache layer 效果也并不会好,根据之前的研究,考虑到高端 SSD 在延迟和 IOPS 上高 HDD 三个数量级,因此哪怕 1% 的 cache miss 也会导致平均 IO 性能降低到预期的 1/10。此外,SSD cache 对长尾延迟帮助很小,而这个是云供应商 SLA 的一个重点。最后,额外的 Cache 层还会造成块存储层的一致性问题,例如 Facebook 在 2010 年就发生过这样的悲剧。
根据上面的介绍,Ursa 使用了 SSD、HDD 混布方案,SSD 作为主副本,HDD 作为备副本,为了弥补之间的巨大性能差距,通过 journal 来将 HDD 上的随机写转化为顺序的日志追加写,再把日志异步 replay、merge 回磁盘。为了提高效率,偶尔的大的顺序写还是直接发到 HDD,跳过 Journal。这篇 Paper 将介绍几个方面:
- SSD-HDD 混布方案的设计,同时为了解决 Journal 和副本的结合带来的复杂性,设计了 efficient LSMT(log-structured merge-tree) 来达到快速的 invalidate 无效 journal 和在故障恢复时快速读取 journal;
- Ursa 中的多个级别的并行,包括磁盘并行 IO、磁盘间的条带化和网络 pipeline,通过这些方法来提高吞吐性能;
- Ursa 的满足强一致性(线性一致性)的复制协议,rich-featured client 和在线升级的高效机制。
实验显示 Ursa 在混布模式下提供了接近全 SSD 的性能,与全 SSD 模式的 Ceph 和 Sheepdog 相比还实现了更高的 CPU 效率。实际环境验证显示能在更少的 SSD 数量下提供全 SSD 部署的 AWS、腾讯云的块存储相媲美甚至更好的性能。
动机
首先我们研究了微软在之前文章发布的数据以及自己收集的数据,显示可以看到 70% 的 IO 大小都小于 8KB,几乎所有 IO 都不大于 64KB,这说明块存储中小 IO 是主要组成。
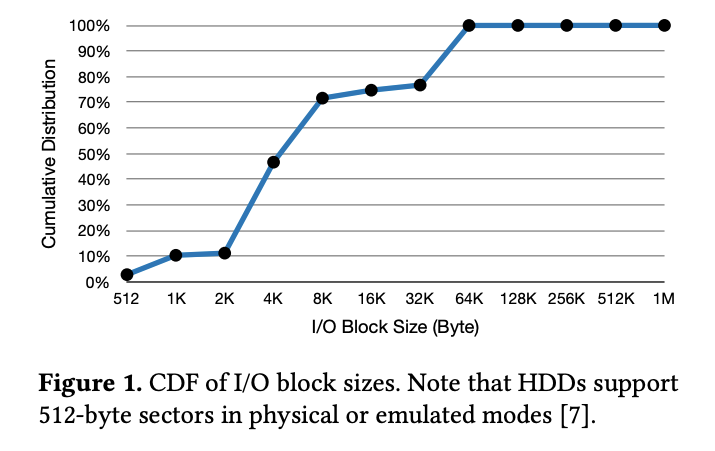
因为 HDD 在随机小 IO 上的低性能,高性能存储往往使用 HDD 来构建,传统的 SATA SSD 比 HDD 在 IOPS 和延迟上要好两个数量级,PCIe SSD 的话更好。而且 SSD 比 HDD 有更低的故障率和相似的寿命。
SSD 的主要缺点就是价格,特别是基于副本的存储。一种办法是使用 SSD、RAM 做 Cache,但是 Cache 效果并不好。
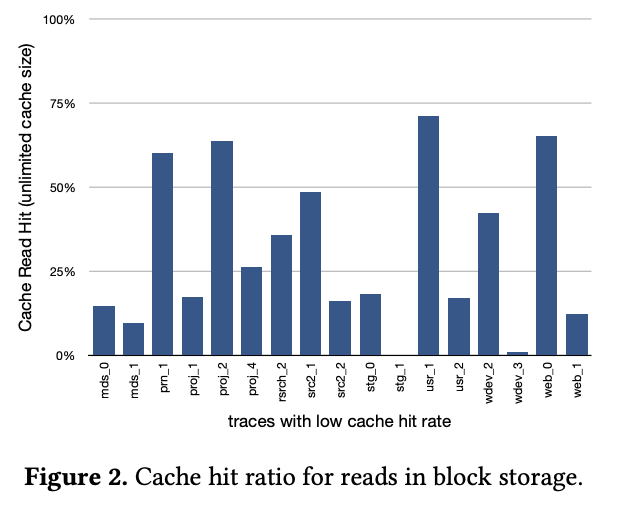
上图显示了在读方面很低的 cache 命中率,因为这里很多数据都是只读一次。再考虑到 SSD 和 HDD 随机 IO 巨大的性能区别,稍低一点 cache 命中率就会很大影响整体性能,而且这种不稳定的 cache 命中会影响云服务的 SLA。
因此这里介绍的 SSD-HDD 混合块存储直接将主副本保存在 SSD 上,然后再复制到 HDD 上,所有客户端读一般来源于 SSD,所以没有 cache miss 的问题,不过问题是如果每次写都要同步复制到 HDD 的话,HDD 的性能会直接拖累这种简单的 SSD-HDD 混布设计,这样就没有意义做混布了,所以这里通过 journal 来弥补之间的差距,在异步 replay。尽管长期看起来看平均写性能还是受限于 journal 在 HDD 上的 replay,但实践中客户端感受到的随机小 IO 要比 journal 的顺序写性能好。
设计
架构概览
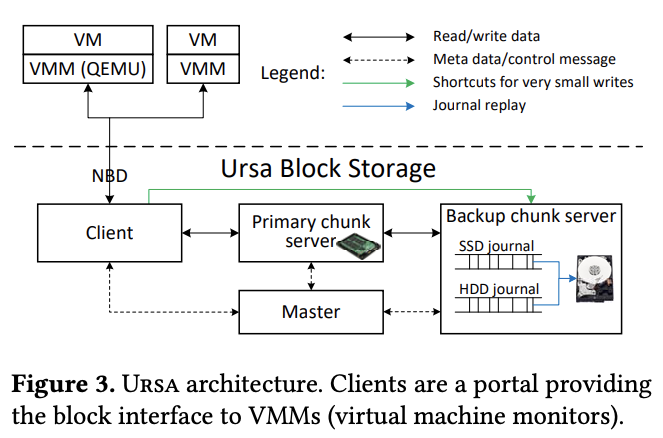
- Chunk Server。每个 data chunk 有一个主副本和多个备副本保存在不同机器,每个机器插多个 SSD 和 HDD,既保存 primary 也保存 backup。
- Client。VMM 通过 client 使用 NBD 接触块存储。client 查询和管理元数据(例如云盘的创建、打开、删除)时与 master 交互。这种交互是 stateless 的。
- Master。Ursa 中有一个类似 GFS 中的 master 来简化管理操作。master 不参与正常的 IO 路径来避免成为瓶颈。master 提供 coordination,包括云盘创建、打开、删除,元数据查询,状态监控,故障恢复等等。
SSD-HDD 混合存储架构
对于一个读请求,primary server 直接读取来自 SSD 的数据,而写请求则先写到 SSD,然后复制到 backup(backup 会在写完 journal 返回),最后返回到客户端。
journal 既可以保存在 SSD 也可以保存在 HDD 上,Ursa 选在保存在 SSD 上因为有更好的并发 IO 性能,此外使用一个 in-memory index 来保存 chunk offset 到 journal offset 的对应。
长期来看,journal 这种方法也会受限于 HDD 的随机写性能,但是:
- 写操作里有很大比例是在 overwrite,而 overwrite 到 journal 可以合并
- 通过 journal 重放时做合并和调度可以减少 HDD 磁头移动
Journal 都保存在 backup 本地,因为本地 journal replay 要比跨机器的 replay 简单很多。根据实践经验,Ursa 使用 SSD 1/10 的容量存放 journal。
按需 journal 扩展
当一个 SSD 耗尽 journal 的空间后,Ursa 可以动态扩展 journal 到另一个负载最低的 SSD(其 journal 空间没有用完)。如果所有 SSD 的 journal 空间都用完了,那就使用 HDD 的空间存放 journal。理论上讲 HDD journal 可以按需任意大,但是和日志文件系统不同(例如 https://www.researchgate.net/publication/221235948_DualFS_A_new_journaling_file_system_without_meta-data_duplication),journal replay 是必须的,不仅是空间效率的问题,还有快速恢复的原因。
HDD journal 设计与 SSD 几乎一样,除了 HDD journal replay 只会发生在 HDD 空闲时。在 Ursa 线上部署的两年时间里,HDD journal 从来没有用到过。这是因为条带将数据分布到很多机器上上,这样很难出现某一台机器集中产生大量写入。而且如果一个客户端产生大量的 IO 会先被 master 限速而不是把 SSD journal 耗尽。
Journal bypassing
大于 64KB 的 IO 会跳过 journal 直接写入 HDD。
Client direct replication
为了降低极小 IO 的延迟,考虑到很小的 IO 只占用极小带宽,小于 8KB 的 IO 会在 client 直接发到 primary 和 backup,不通过 primary 来复制。这个是这样算出来——每个机器两个万兆网口,希望最多只用一半的带宽,然后提供给客户端最高 40K 的 IOPS,考虑到三副本,那就是 20Gb/2/40K/3 ~= 10.4KB,所以设置为 8KB。
Journal index
因为上面介绍的 bypass,数据复制和恢复的复杂度会上升。为此 Ursa 设计了 per-chunk in-memory index 结构,map 了每个 chunk ofsset 对应 journal offset,这样可以快速 invalidate journal 和快速恢复。
journal index 一般通过 LSMT 设计,然后原本的 LSMT 无法满足 Ursa 在 invalidate 和 recovery 时的要求:
- LSMT 的 index 的 key space 是连续整数
- LSMT 的 index 查询和更新对 journal 读写有着严重影响,所以会直接决定 Ursa 的 IO 性能
因此 Ursa 对 LSMT 做了一下优化,显著提高了 range query 和 range insertion 的性能。
Composite keys
如果 key 对应的 journal offset 是连续的,那就合并为一个 composite key {offset, length}。composite key 之间定义了 LESS 关系:x LESS y iff x's offset+length <= y's offset,这样 composite key 形成了一个有序关系。
Index operations
因为上面定义的有序关系,因此快速的查询和更新就可以很快。
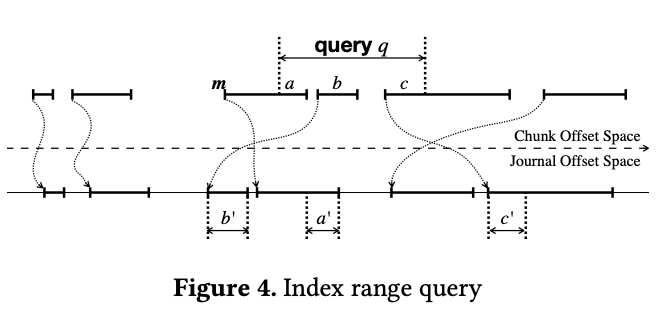
Index storage
KV({offset, length} -> j_offset)保存为一个 8 字节的结构体。Ursa 在 KV 中保存的是一个两级结构,第一级是红黑树,高插入效率,低存储效率,第二级是有序数组,插入效率低但存储效率和查询效率高。
当新增一个 KV 的时候,Ursa 首先快速插入到红黑树,然后由后台的低优先级工作线程异步合并到数组。因此数组中保存的 KV 可能是过期的(红黑树中的数据还没有同步到数组),所以查询查询时会先查询红黑树,然后在对 missed range 去数组查询。这样一级红黑树实际上是二级数组的一层小容量 cache。对于数组,8GB 的内存可以保存十亿条记录,相当于在 16TB journal 上全部以 16KB 的 IO 写入所需要的记录数量(16TB/16KB)。
多个层面的并行
磁盘层面
为了充分利用 SSD 的并行 IO 能力,每个 SSD 会运行多个 chunk server 进程,每个进程使用一个 libaio 线程。进程内 Ursa 会把 libaio 事件转换为协程,通过一个同步调用接口来隐藏 libaio,相反的,HDD 上只运行一个单线程进程,不使用 libaio。
跨磁盘层面
跨磁盘层面有三种并行机制,包括:
- 条带化
- 乱序执行
- 乱序完成
首先,Ursa 将一个虚拟机磁盘分割成多个固定大小的 chunk,然后两个或多个 chunk 组成 strip group,这样大的读写可以并行在多个 chunk 上。service manager 来保证数据 placement policy,即一个 strip group 的所有 chunk 不在同一磁盘或物理机上。
其次只要 IO 落在在不同的 chunk 上,Ursa 就允许它们乱序执行。
最后 Ursa 支持乱序返回。比如对某个 chunk IO 请求顺序是先有请求 r1,然后是请求 r2,那么返回时可以相反。
网络层面
网络拥塞和操作系统调度可能造成端到端的延迟。Ursa 的做法是使用对每个链接使用 pipeline 来处理 IO 请求,这样网络延迟对总体的 IOPS 和吞吐的影响就小很多。不过这样显然会有对上层的崩溃一致性的问题(因为完成顺序和发起顺序不一致),这个应当由上层来保证,例如 Linux Ext4、XFS 都有 journal 机制,OptFS 有 osync 和 dsync 来保证最终一致和持久化时保持一致(MatheMatrix:我觉得可以参考 OSDI 14′ 的这篇文章 https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-pillai.pdf,以及我们实际遇到过的,一些文件系统并不一定达到了完整的崩溃一致性)。
一致性
概览
Ursa 通过 chunk server 间的 totally ordering write 来提供对每个 chunk 的线性一致性。简单来说,Ursa 的复制协议和 Paxos、Raft 这样的 RSM(Replicated State Machine)是同源的。每个 chunk 有版本号,chunk server 和 master 共同维护持久化的视图号(view number),view number 会在故障恢复后分配新 chunk server 时更新。
当客户端打开虚拟磁盘时,客户端会从 master 获得每个 chunk 的视图号和位置,然后向所有 replica 查询它上面的视图号。一旦视图号得到确认,client 会选择一个 replica 作为主副本(一般是 SSD 的那个),然后对主副本做读写请求,如下图。

如果 client 检测到某个 replica 失效,就会汇报到 master 重新分配一个 replica,更新 chunk 的位置,增长视图号。
尽管 Ursa 的复制协议 follow 了经典的设计原则,但是还是有两方面明显不同。其一是 Ursa 保证任意时刻只有一个 client 可以 access 虚拟磁盘(MatheMatrix:如果客户需要共享云盘?后面有解答);其二是混合错误模型来区别对待副本和网络失效。
Single client
Ursa 通过租约和锁协议来保证任何时候最多只有一个虚拟机可以某一个云盘读写数据。这样大大简化了强一致性设计。Client 会周期性 renew 租约,一般是 10s。如果有多个 VM 挂载同一个云盘,会在任意一个物理机上使用一个虚拟机通过类似 OCFS2 的集群文件系统协调 IO 请求,对所有挂载的 VM 提供服务。
混合错误模型
不同 GFS 这种同步复制系统(f+1 份拷贝,允许 f 个失效)或其他的异步复制系统(2f +1 份拷贝,允许 f 个失效),Ursa 将副本和网络的失效区分对待,类似 VFT、XFT 这样。Ursa 中 client 会尝试写到所有副本,但会有一个超时时间,如果发生了超时,只要主副本成功即可 commit(上图的第六步)。同时 client 会通知 master 来修复问题,例如分配一个新的 replica 来替换。
与同步复制系统相比,这样可以在一些 replica 失效时始终保持系统可用,和异步复制系统相比持久性更好,具体来说,Ursa 可以在下面的情况保持持久性:
- 2f+1 中不多于 f 个副本失效
- (失效副本数)+(链接故障数)< 总副本数
(MatheMatrix: 这里我一开始没看懂,后来咨询了本文主要作者之一李慧霸博士,这里的核心含义是 Ursa 会先尝试同步复制,但超时则降级到异步复制,从而实现用户视角的服务可用性)
Ursa 复制协议
一般情况
初始化
当打开虚拟磁盘时,客户端将从 master 获得所有 chunk 的位置和视图号,然后一步查询每个 chunk 的所有 replica 的版本号和视图号。如果一个 chunk 的所有 replica 都有与 master 保存的一致的 view number,那么就可以从中任意选一个作为 primary(优先选择 SSD 上那个);否则,客户端会先向 cluster director 通知修复一致性,然后再重试。因为前面介绍的 single client 设计,client 其实是可以在任意时间更换 primary 的选择。
读和写
一旦视图号和 primary 得到确认,client 就可以向 primary 发送读写请求了。其中读请求优先由 primary 处理,写请求则会带着 client 的 view number 和 version number。还是上面的图,当收到写请求时,primary 会先检查本地的 view number、version number 是否和这个写请求一致,如果一直就在本地写,同时复制到 backup,增长 version number,最后回复给 client。backup 上的操作也是类似的。
然而,如果 client 的 view number 和请求的不一致,那么 primary 会拒绝并回复给客户端。client 需要从 master 获得现在 view number,如果 client 的 view number 大于 primary 上的,那么 primary 将尝试通过增量修复来更新自己的状态,增量修复就是从其他副本同步修改过的数据。如果 client 的 版本号等于 primary 的版本号减 1,那么 primary 本地不会做这个写请求(因为 primary 实际已经执行过这个请求),但是会转发到其他 backup。考虑到 single client 的前提,client 的版本和 primary 的差不会大于 1.
前面介绍的混合错误模型一方面提升了系统的可用性,但也增加了数据持久性的难度。具体来说:
- 正常情况下,所有 replica 写入成功即 commit
- 如果 primary 无法从所有 replica 获得成功写入的消息,那么会等待一定时间看能否获得半数成功(这样加上 primary 就是多数成功)
- 与此同时,client 会通知 master 去修复不一致问题,或者可能最终就是分配一个新的 replica 替代失效的 replica
更换主副本
如果 client 读写发到了一个 fail 的 primary,那么 client 应该会自主更换 primary 到一个有最新数据的 backup 上,这样来实现高可用。考虑到使用了 SSD journal,即使此时是在 HDD backup 上,写入性能也不会太受影响,不过读取性能此时还是会受影响的。此时 cluster director 会同步在 SSD 上再创建一个新 replica,最终 client 会将 primary 重新移回到 SSD 上。
增量修复
为了支持增量修复,每个 replica(包括 SSD 和 HDD)都在内存里保存了一个 journal lite,cache 最近的写请求的 position、offset 和 version number。当一个 primary 或者 backup 从临时故障恢复时(例如网络分区),相关的 replica 会发送他自身当前的 version number 到其他 replica,其他 replica 收到时:
- 根据请求的 version number 查询 journal lite,找到修改的数据
- 根绝 journal lite 里的信息构造修复消息
- 修复消息里加上新的 version number,回复给 replica
如果无法通过 journa lite 找到数据(比如因为垃圾回收),那么就会传送完整数据。
Client-directed replication
前面提过这个事情,就是小于等于 8KB 的 IO 会由 client 直接送到所有副本,而不是通过 primary,其 version number 的维护是类似的,这样可以显著降低小 IO 的延迟。
错误恢复(View Change)
当发生了不一致问题时,master 会向具有最高 version number 的 replica 发送请求来做增量修复。反之如果是 chunk 有问题,那么 master 最终会分配一个新的 replica 来替代问题的,view number 会更新为 i+1,client 会在下次读写时得知这次 view number 的变化。
更具体地说,master 会从多数 replica 中收集 version number,然后选择其中最大的 version number vm 作为最新 state,将数据分发到新分配的 replica,如果需要的话,同时对已存在的 replica 做增量修复。
最后,所有的 replica 将 view number 更新为 i+1,因为它们此时有相同的数据(以及相同的 version number vm)。如果 master 和一个 replica 同时故障了,那么先修复 master,然后修复 replica。
故障恢复的核心思想就是 master 从 quorum 中找到最高的 version number,这个和异步复制系统是一样的。这个方案的缺点就是如果多数 replica crash 则存在丢数据的可能。相反同步复制系统可以在哪怕只有一个幸存者时工作。
下面这里的讨论看起来是如何通过识别 majority 中的永久 crash replica 来达到即使只有一个幸存者 依然可以找回数据,目前 Ursa 的做法还比较依赖手工。
讨论
特性丰富的 Client
Ursa 将很多特性例如 tiny write replication、striping、snapshot、client-side caching 都放在了 client。这和与 Qemu 的紧密集成有关。
Client 被设计为装饰器模型的 pluggable modules,所有 module 实现了公共的 read()/write() 接口,client 可以在线无感升级。
在线升级
Client
当 client 和 VMM(qemu)断开连接时,VMM 不会自动重连,所以想在不影响 Guest 的前提下升级还是比较难的。一种思路是把代码尽可能放到 shared library,这样升级就是 dynamic reloading,就很简单,但是也有很多限制,比如现有很多静态库不适合,接口不好升级等等。因此 Ursa 升级粒度是 process 而不是 library。Ursa 将 client 分为两个 process——core 和 shell。当升级时:
- core 停止从 VMM 接受新 IO,将 pending IO 完成
- 将状态保存到一个临时文件
- 退出并返回一个特殊返回码
shell 进程接收到 exit code 启动一个新的 core,从临时文件读取状态并恢复。
(MatheMatrxi:大体就是一个通过外包壳来分离核心代码的思路,升级期间 IO 应该都 pending 了)
Master
Master 升级是比较简单的,因为不涉及 IO 路径,只要关掉旧的立刻启动新的即可。升级期间磁盘创建和空间分配都会失败,不过客户端会自动重试。
Chunk Server
这个就比较难了,特别是在 chunk server 升级中发生 failure 时会对 failure handle 产生 confuse。所以 Ursa 设计了一个优雅热升级的策略:
- 发送一个特别信号到 chunk server;
- 关闭服务端口,停止接收 IO;
- 等待 in-flight io 结束;
- 等待新的 chunk server 启动;
- 检查新 chunk server 正常工作。
如果热升级成功了,旧的 chunk server 关闭所有连接( MatheMatrix:比如管理端口的连接)退出,客户端自动重连到新的 chunk server。反之如果失败了,旧的 chunk server 会杀死新的 chunk server,重新打开服务端口继续提供服务。
逐个升级
一个 Ursa 集群有众多服务进程做成,升级时每次升级一个进程,检查状态再升级下一个。所以升级集群可能会持续好几天时间。所有组件保持向后兼容性,到目前 Ursa 在一个部署超过两年的集群里对 replication protocol 升级过四次版本,每次升级都会增加新的操作并保证之前的操作不会发生变化来达到向后兼容。
发挥磁盘并行性
根据经验,Ursa 对 SATA SSD 和 PCIe SSD 会跑两个和四个进程,HDD 上跑单线程单进程,这个线程同时处理 journal replay、small write 和 replication( large write)。评估显示单线程进程只用电梯算法就可以跑满 HDD,多进程、多线程这些都会扰乱电梯算法,降低性能。
硬件可靠性
根据统计(下面的表格),HDD 贡献了 70% 的错误,比 SSD 高一个数量及。而 SSD 的 wear leveling(损耗平均)保护了 SSD 不会被频繁的 journal 写影响寿命。

不过虽然 SSD 平均故障率比 HDD 低,但是有一个潜在风险就是 SSD 可能因为固件 bug 造成同一批、同一个供应商的 SSD 批量出现问题。(MatheMatrix:然后举了腾讯云去年的例子 /捂脸)
为了解决这个影响,需要增加购买 SSD 的多样性,而且把 primary chunk 和 backup chunk 的 journal 存放在不同批次、供应商的 SSD 上。和全 SSD 存储不同的是 Ursa 可以通过 HDD 避免因为 SSD 固件 bug 造成的批量 SSD 下线造成数据丢失。
局限
- primary replica 故障恢复时客户就需要忍受 HDD 的性能影响,这要求我们尽可能缩短降级时间;
- 因为每个机器能提供的 SSD journal 大小有限制,SSD journal 无法持续性提供长时间很高的随机写(这个在美团云服务中比较少见),这个通过 HDD journal 和限速来 work around;
- SSD 的实效恢复要比全 SSD 更 urgent(MatheMatrix:和 1 好像一样)
- 对 SSD 的大小要求比 SSD cache 大很多
评估
这里做了一些测试,我直接展示数据吧,比较了 Ursa(SSD 和 SSD-HDD 混布)、Ceph 和 Sheepdog:
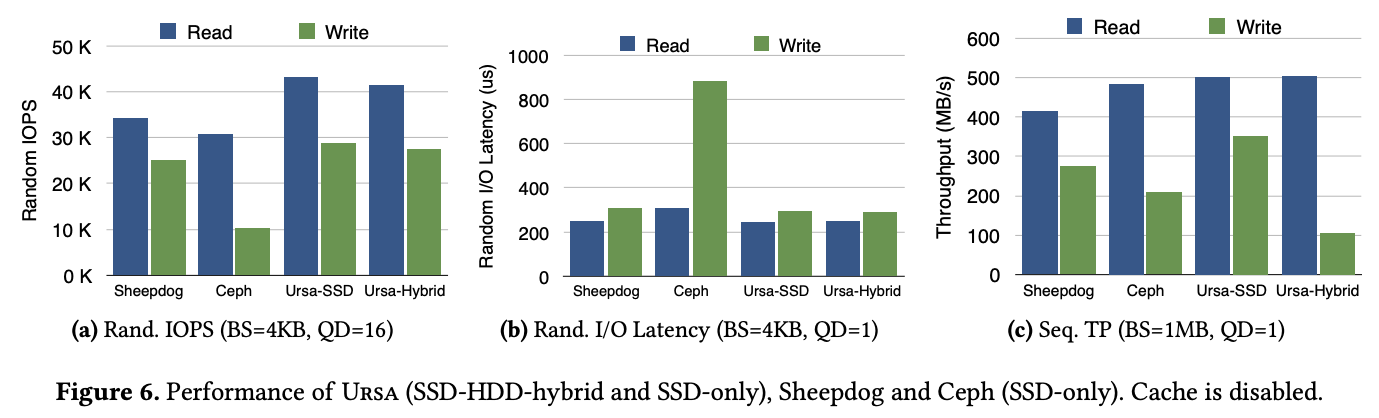
QD(queue depth)最大为 16 因为 qemu NBD driver 只能提供到 16。Sheepdog 和 Ceph 都是部署在全 SSD 环境的。(c) 这里表现比较差主要是因为 1MB 的 BS 大于 64KB 的 journal pass 阈值,所以 backup 都直接写入 HDD 跳过 journal 了。
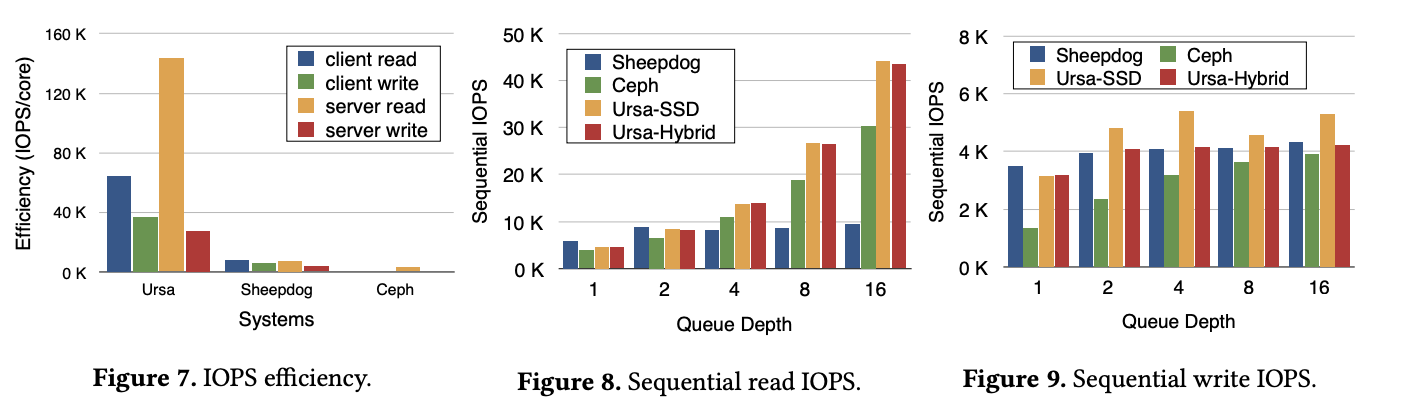
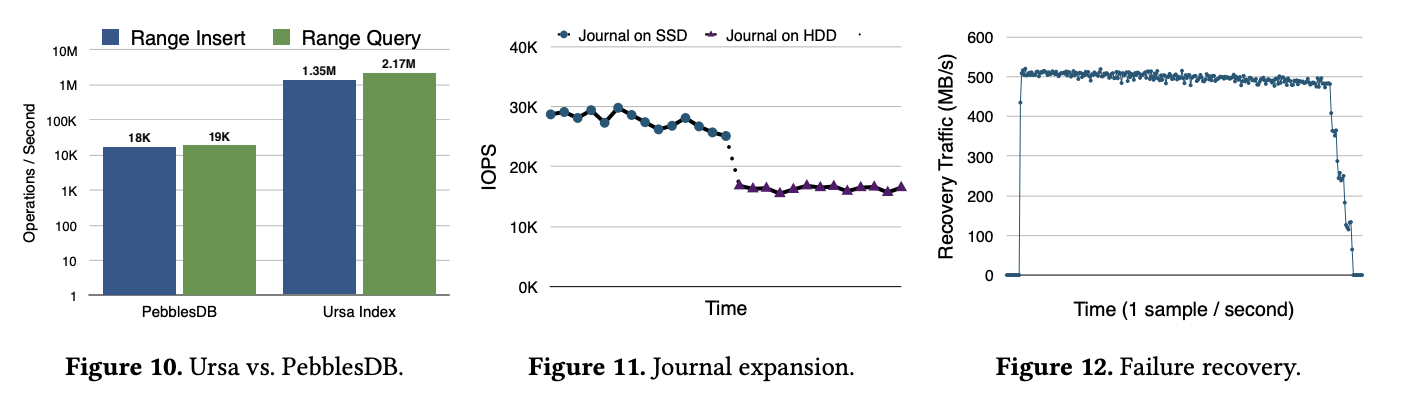
图 10 主要是因为 Ursa 很依赖 journal 的 range query 的性能,因此和 PebblesDB 做了一个比较。
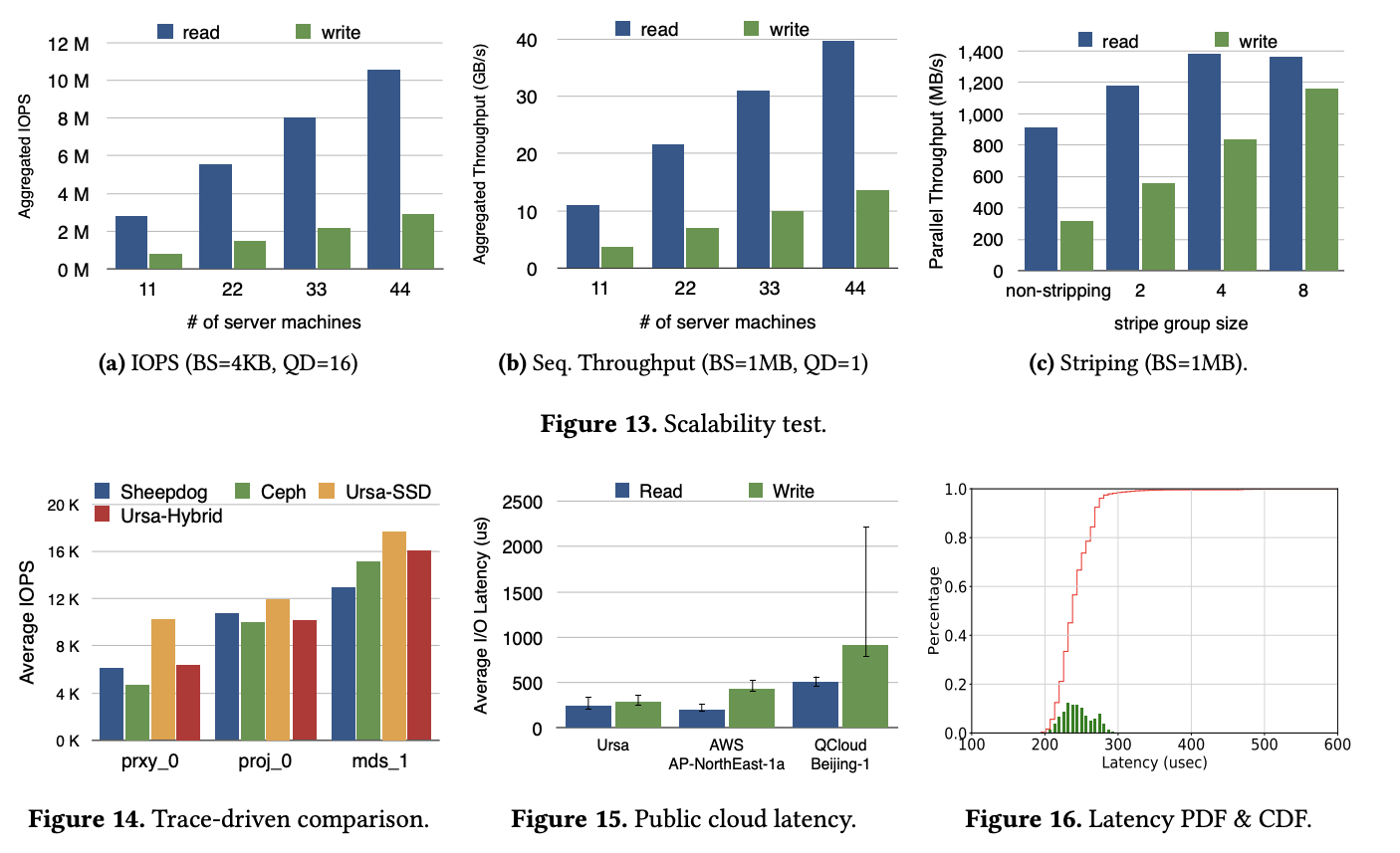
图 14 这里的选取了三种有代表性的 trace 数据 prxy_0、proj_0 和 mds_1 分别代表不同的 IO pattern。
相关工作
这里举了一些块存储、EC、混合存储、文件系统、对象存储和一致性的文章
总结
未来计划 RDMA/DPDK/SPDK 来达到超低延迟;提高顺序写的 IOPS。
Ursa 的一部分组件是开源在 http://nicexlab.com/ursa/ 的,包括:
- st-pio 前面说的 libaio 的包装
- st-redis hiredis 的包装
- logging lib 支持东岱更新配置的轻量级 logging library
- crc32 高性能的 crc32 library
- testing script
后面是致谢和线性一致性的正面,包括 normal case 和故障恢复。