Contents
前言
devconf 也是我比较关注的一个 summit,devconf 的内容当然比较偏实践,但有一些东西还是比较前沿的。
很多人会认为 virtio 是一套实现(virtio-net, virtio-blk 等等),但实际上 virtio 是一套标准(或者说抽象层),因为 virtio 通过半虚拟化的方式来加速虚拟化的性能,那么就需要 hypervisor 和 guest 的协作来达到目的,其中 hypervisor 端我们称为 backend driver,guest 端称为 frontend driver。
virtio 的具体介绍在 developer works 有一篇很好的文章,如果对 virtio 不了解的话可以参考这篇: https://www.ibm.com/developerworks/cn/linux/l-virtio/index.html,进一步的,还可以阅读 Rusty 写的原论文:https://www.ozlabs.org/~rusty/virtio-spec/virtio-paper.pdf
这里简单介绍一下 virtio 的基本架构,就是下面这张图:
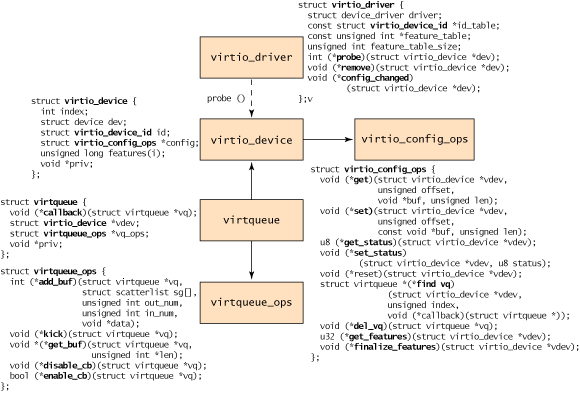
可以看到 IO 的核心就是 virtqueue,virtqueue 定义了 add_buf、get_buf、kick 等几个关键 IO 接口。
virtio 刚提出时其实是很先进的,因为通过共享内存替代了完整的 trap/模拟过程,大大提升了性能,但是随着底层 IO 设备性能的越来越强,大家对 virtio 也逐渐提出了更高的要求,例如通过 vhost 来加速等等,但是即使像 vhost、vhost-user 这些技术也解决不了对 hypervisor 资源(特别是 CPU)的占用问题,因此需要更加适合高性能 IO 设备的技术了。
一种思路是设备透传,作者在这里简单讲了下设备透传的缺点:

主要是一来热迁移很难做,当然并不是说完全不能,今年的 KVM Forum 上就有 topic 讲 GPU 透传怎么做热迁移,Netdev 也有讲 SRIOV 网卡怎么做透传,但有几个问题:
- 热迁移实现和透传设备类型强相关,例如上面 GPU 的热迁移和 SRIOV 网卡的设计完全不同
- 需要很多的代码改动,不能复用现有的 virtio 设备热迁移框架
- 更加灵活可控
为此 oasis 现在发布了 virtio 1.1 spec,在 devconf 时还是 draft 阶段,现在已经正式发布了:https://docs.oasis-open.org/virtio/virtio/v1.1/csprd01/virtio-v1.1-csprd01.html。virtio 解决的核心问题就是性能,这个不仅包括软件实现的性能,也包括硬件实现的性能(和实现的难度)。
设计
Packed virtqueue
首先 virtio 1.1 最重要的改变之一就是 virtqueue 的改变,由 split virtqueue 转为 packed virtqueue。这里我要先讲一下 split virtqueue 是什么,以及遇到了什么问题再讲 packed virtqueue。
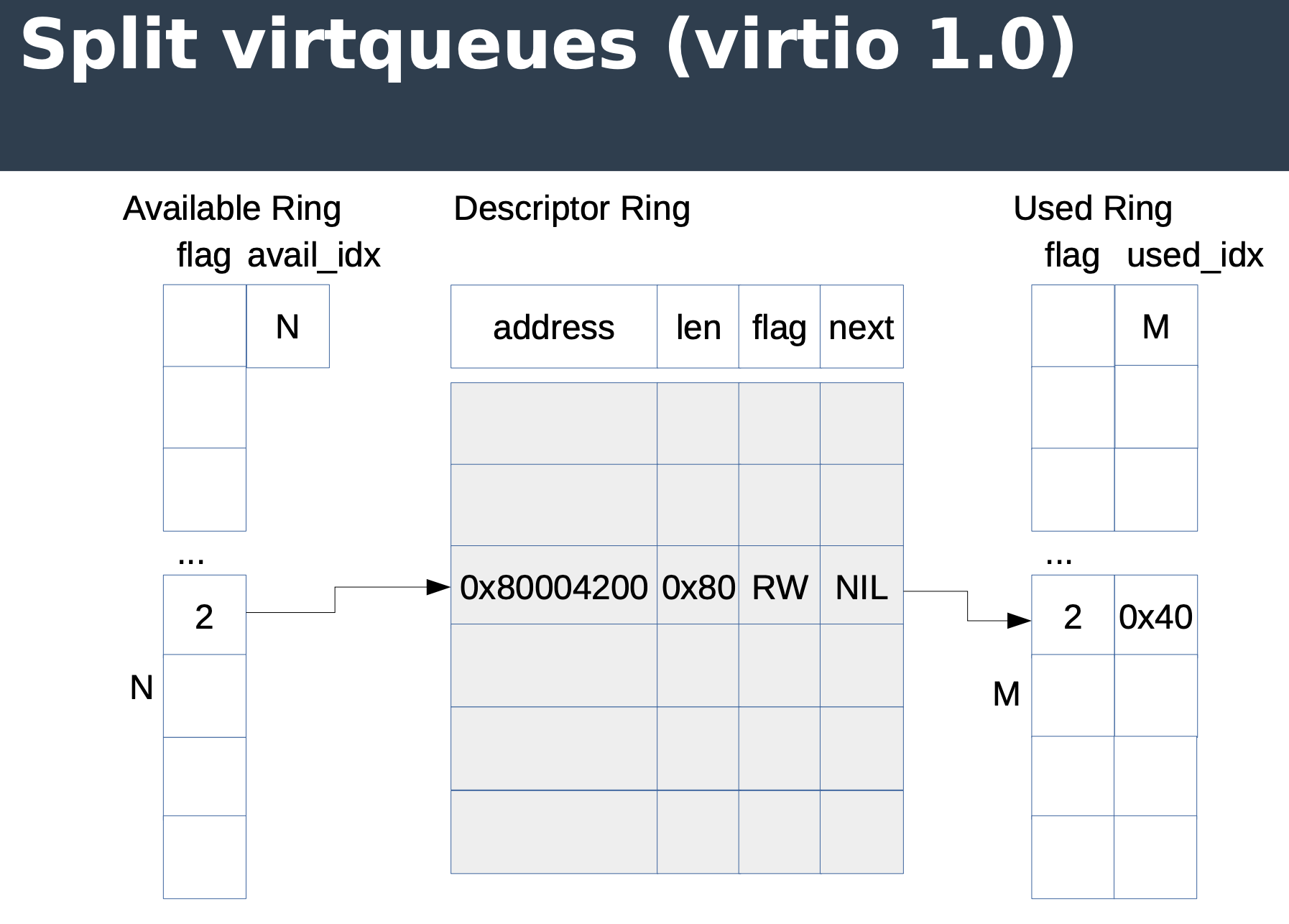
本节的图来自去年的 DPDK Summit,Jason Wang(Redhat)和 Tiwei Bie(Intel)在去年 DPDK Summit 对 Virtio 1.1 做了很好的介绍,推荐阅读,原 Slide 在:https://www.dpdk.org/wp-content/uploads/sites/35/2018/09/virtio-1.1_v4.pdf
Split virtqueue 顾名思义,queue 会有多个 ring,分别是 available ring、descriptor ring 和 used ring,每条记录都通过
next 指针来标识下一条记录,这样就会有下图所示的几个问题,而且对于硬件实现来说,这些跳转会带来开销比较高的 pci transaction,不利于性能提高。

下面的是 packed virtqueue,packed queue 把原本分散在三个 ring 的元数据组合在了一起,这样元数据读取的软件实现可以减少 cache miss,硬件实现可以只用一个 PCI transaction 解决。
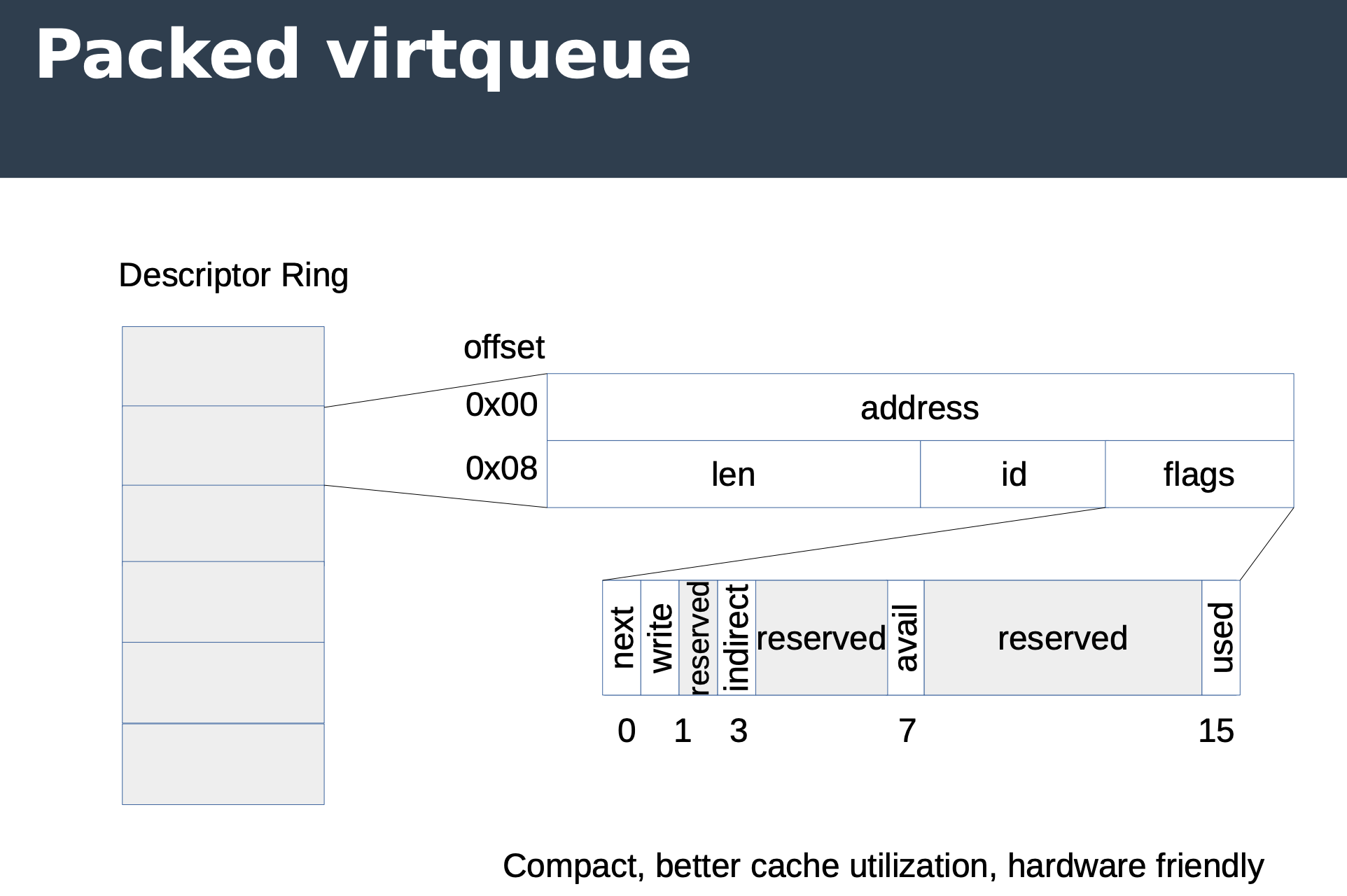
其他
另外就是一些新的特性,这些特性需要在设备 negotiate 时决定是否开启,比如:
- in-order completion。以往 ring 的完成是可以乱序完成的,这样 driver 实现就需要做的更复杂,也不利于优化(比如不好做批量动作)
- 支持内存访问有限制的设备(比如设备的内存访问要经过 IOMMU)
- 支持开启关闭特定 ring buffer 的 notification,硬件实现可以减少 PCI transaction
- notification 增加更多的信息,这样硬件实现上可以并行做更多事情,而且减少了在 PCI bus 上来回获取信息需要的时间。
目前的状态
硬件实现是需要看供应商的,所以这里除了 paper work 之外我们还可以说下目前软件实现的状态。
Packed virtqueue
packed virtqueue spec 其实已经定下来了,也发布在了 1.1 spec 中,对应实现需要 front 和 backed 都改,所以当前状态如下:

dpdk 这边进展是比较快的,通过 dpdk 理应已经可以测试 packed queue 带来的效果。
vDPA
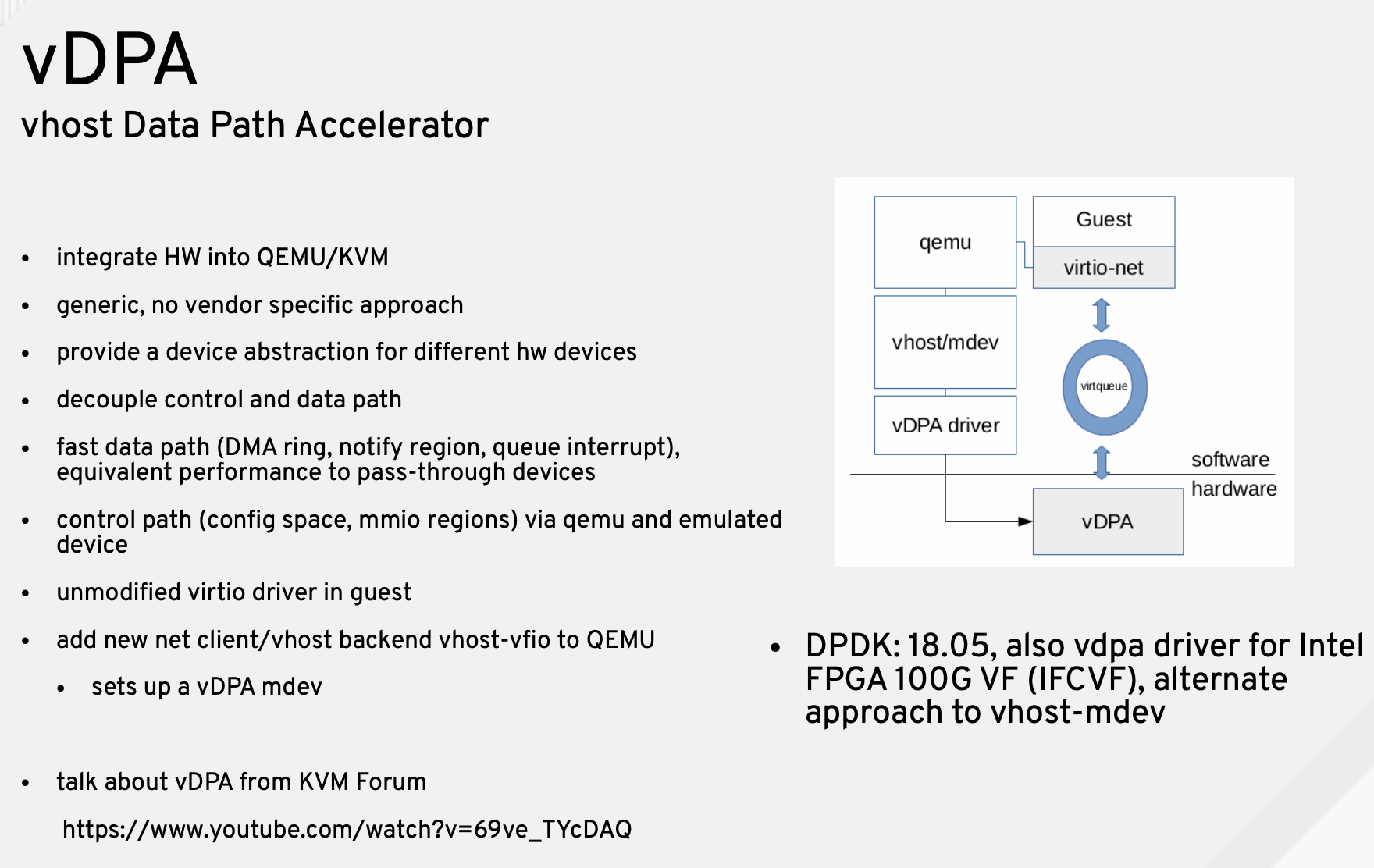
即使有了上述规范,实现一个硬件 backend 的 virtio 设备也是比较繁琐的,因此 Intel 提出了 vDPA 这个框架,可以理解为如果你真的打算用硬件来做 virtio backend,vDPA 帮你把通用的一些工作已经做好了,例如硬件设备抽象、IO 路径等等,Intel 目前给出了 vDPA 下两个驱动,一个是 IFCVF,用来支持 Intel FPGA 100G,不过这个 FPGA 开发板可是很贵,后来 Intel 又提供了 vDPA Sample,这样你可以从中学习 vDPA 的工作方式。
vhost-mdev
vDPA 其实挺好的,但 Intel 后来又提出了 vhost-mdev,上面 vDPA 的架构图你也能看到有个 vhost/mdev,这是为什么呢?在我看来主要是因为 vDPA 原本设计比较面向网络,我们要先看下 vDPA 的原本设计细节架构(摘自 kvm forum 2018):
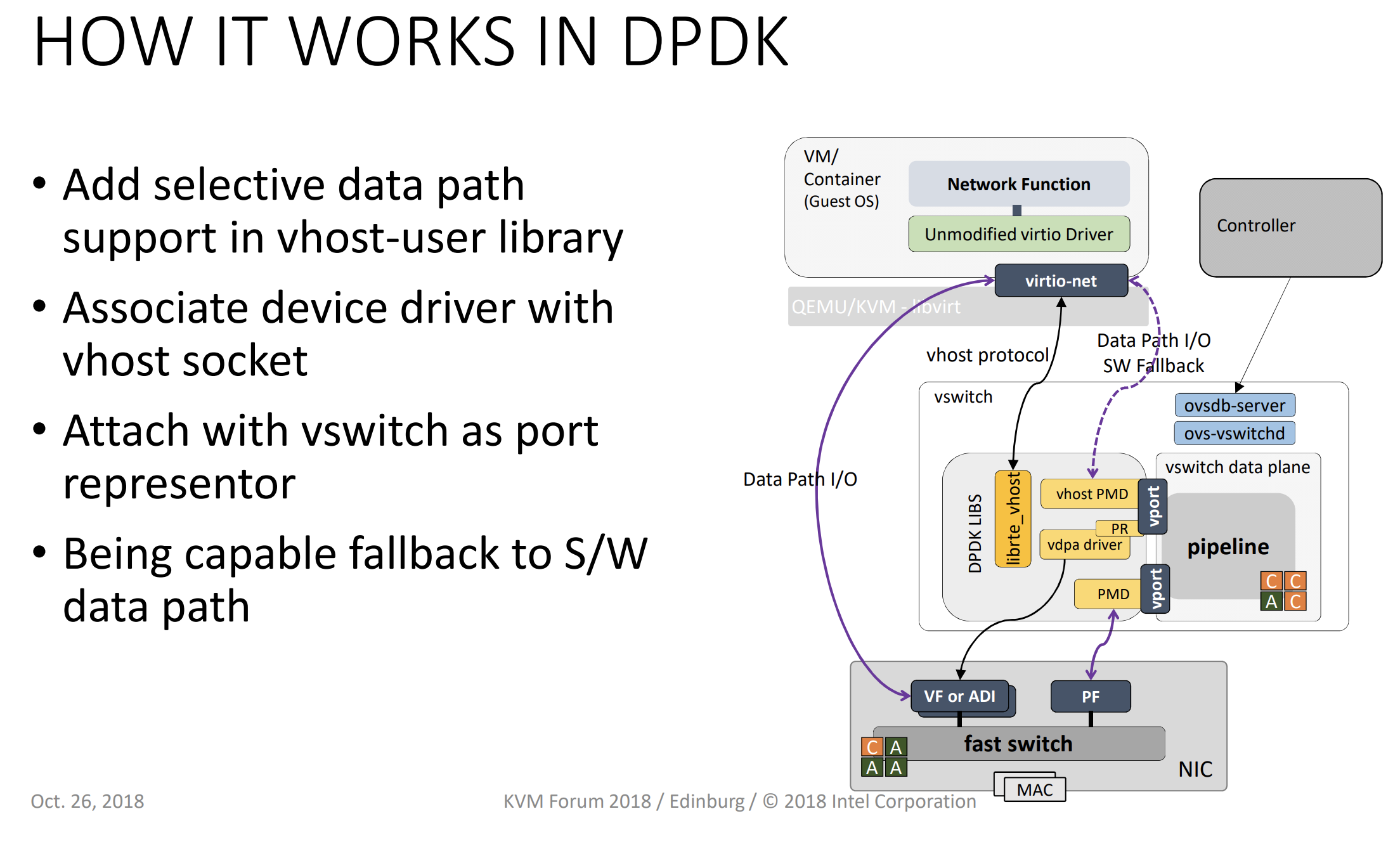
可以看到 vDPA 做了数据面,但是控制的部分其实是 virtio-net(vhost-user)实现的,这样在刚开始做 vDPA 来说很方便,因为减少了很多工作,但如果面向别的类型设备准备实现 virtio 硬件加速,比如存储啊、一些辅助加速设备啊什么的就会发现 vDPA 帮我们减少了数据面的代码量,但控制面还是需要很多工作。就像 vDPA 在 DPDK 里做 vdpa driver 这样解决 vhost 到 vDPA 这个过程。
有没有什么通用 IO driver 呢,其实是有的,vfio。
所以我们可以在前端使用 vfio,在后端做一个 mdev 对接下面具体的 virtio 加速设备,厂商可以自定义 MMIO、PCI 空间等等这些控制面细节。
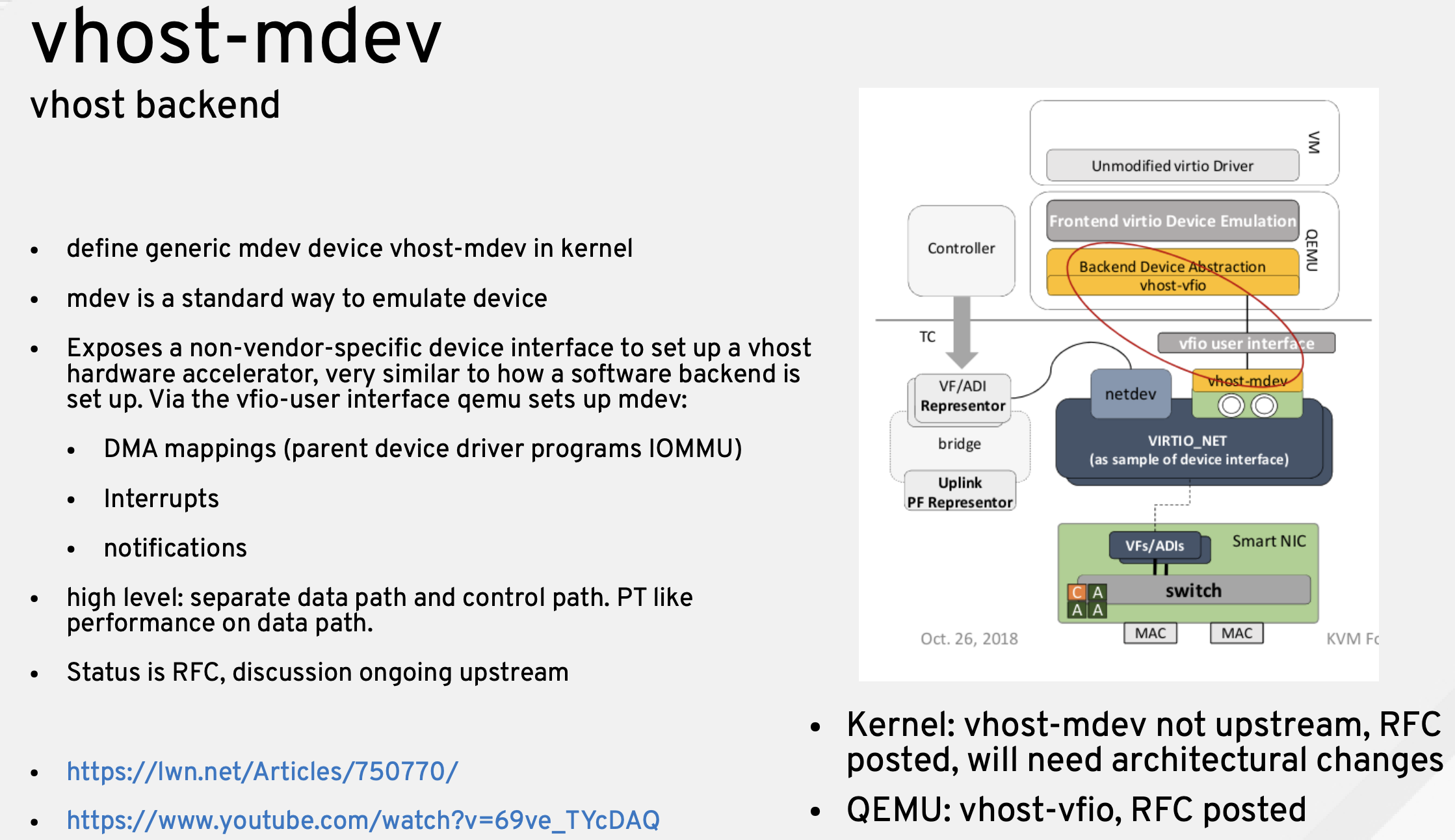
vhost-mdev 目前还处于比较早期的阶段。
Intel Cascade Glacier
我对 FPGA 很多内容也不了解,只知道这个是 Intel 去年正式发布的 FPGA 智能网卡,可以实现 virtio 加速,OVS 卸载,从 Intel 在去年 OVS Conf 的介绍看,Intel 为之提供了一套 SDK 和软件栈。
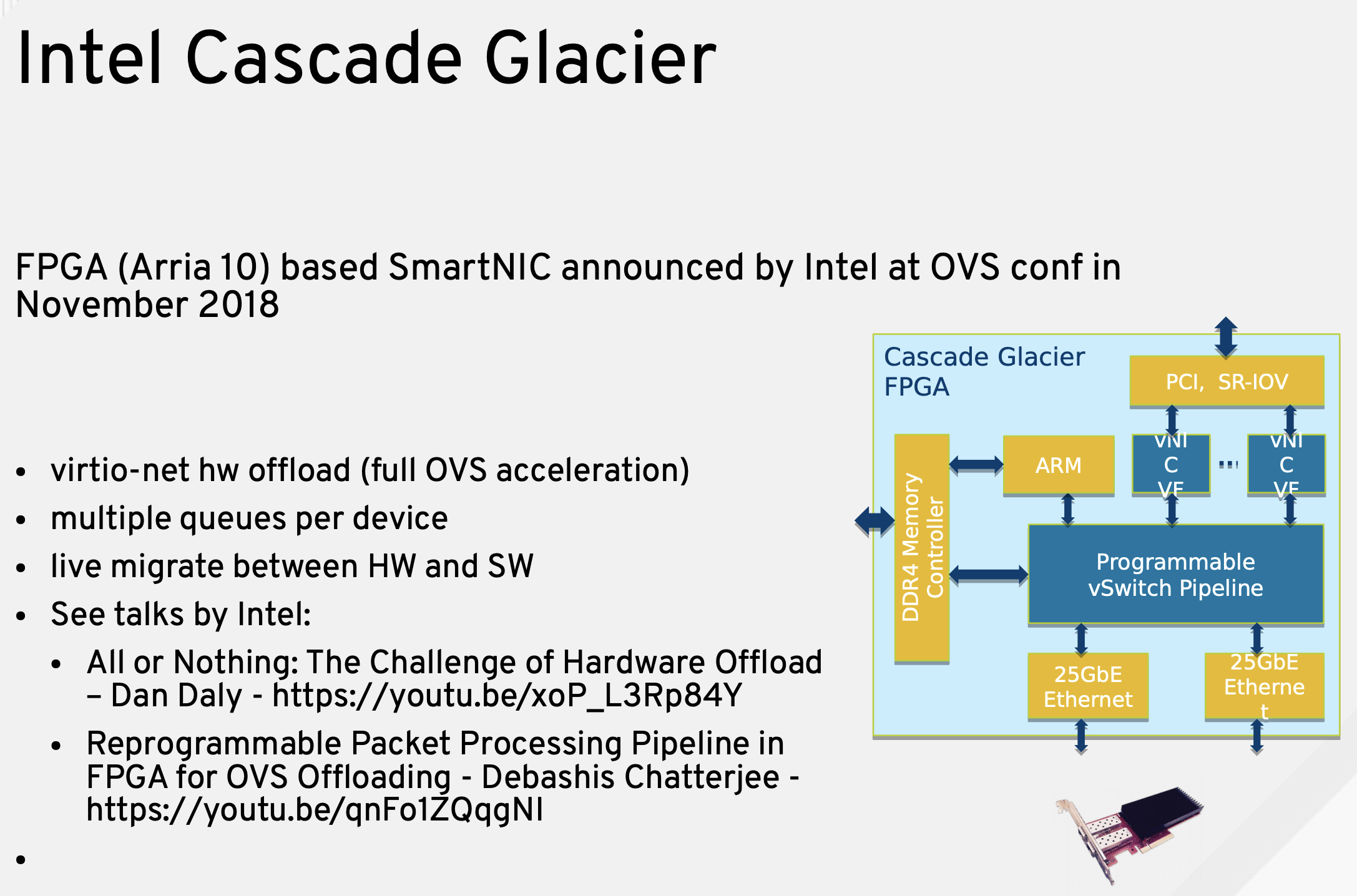
此外还支持 P4:
总结
- 越来越多供应商开始对 virtio 硬件加速感兴趣
- 目前已经有至少一个硬件 ready
- 有通用的软件框架支持各种硬件
- Virtio 1.1 为硬件实现做了很多优化和改进
One thought on “devconf 19′: virtio 硬件加速”